# 前端架构与性能优化那些事
# 前端的性能到底对业务数据有多大的影响
来个小故事
从前有个工程师,特别注重代码细节,有一天他发现系统中的一段代码写的性能很差,因此,他用汇编重写了整段代码,执行效率足足提升了三倍。但是最后,大家发现,用户反馈性能丝毫没有提高,因为他优化的那个进程名字叫“System Idle”。
所以你看,性能优化不能只着眼于局部的代码。这里,我要提出一个我的观点:一切没有 profiling 的性能都是耍流氓。凡是真正有价值的性能优化,必定是从端到端的业务场景建立体系来考虑的。
总结:性能体系的建立可以分成以下几部分:
1.现状评估和建立指标;
2.技术方案;
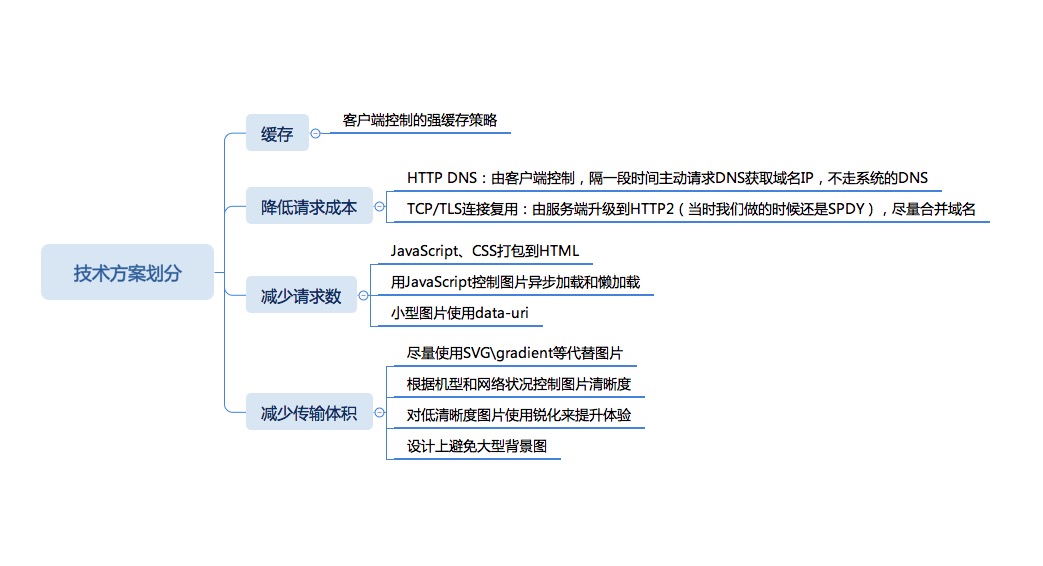
3.执行;
4.结果评估和监控。
57%的⽤用户更更在乎⽹网⻚页在 3 秒内是否完成加载。 52%的在线⽤用户认为⽹网⻚页打开速度影响到他们对⽹网站的忠实度。 每慢 1 秒造成⻚页⾯面 PV 降低 11%,⽤用户满意度也随之降低降低 16%。 近半数移动⽤用户因为在 10 秒内仍未打开⻚页⾯面从⽽而放弃。
# 性能优化学徒
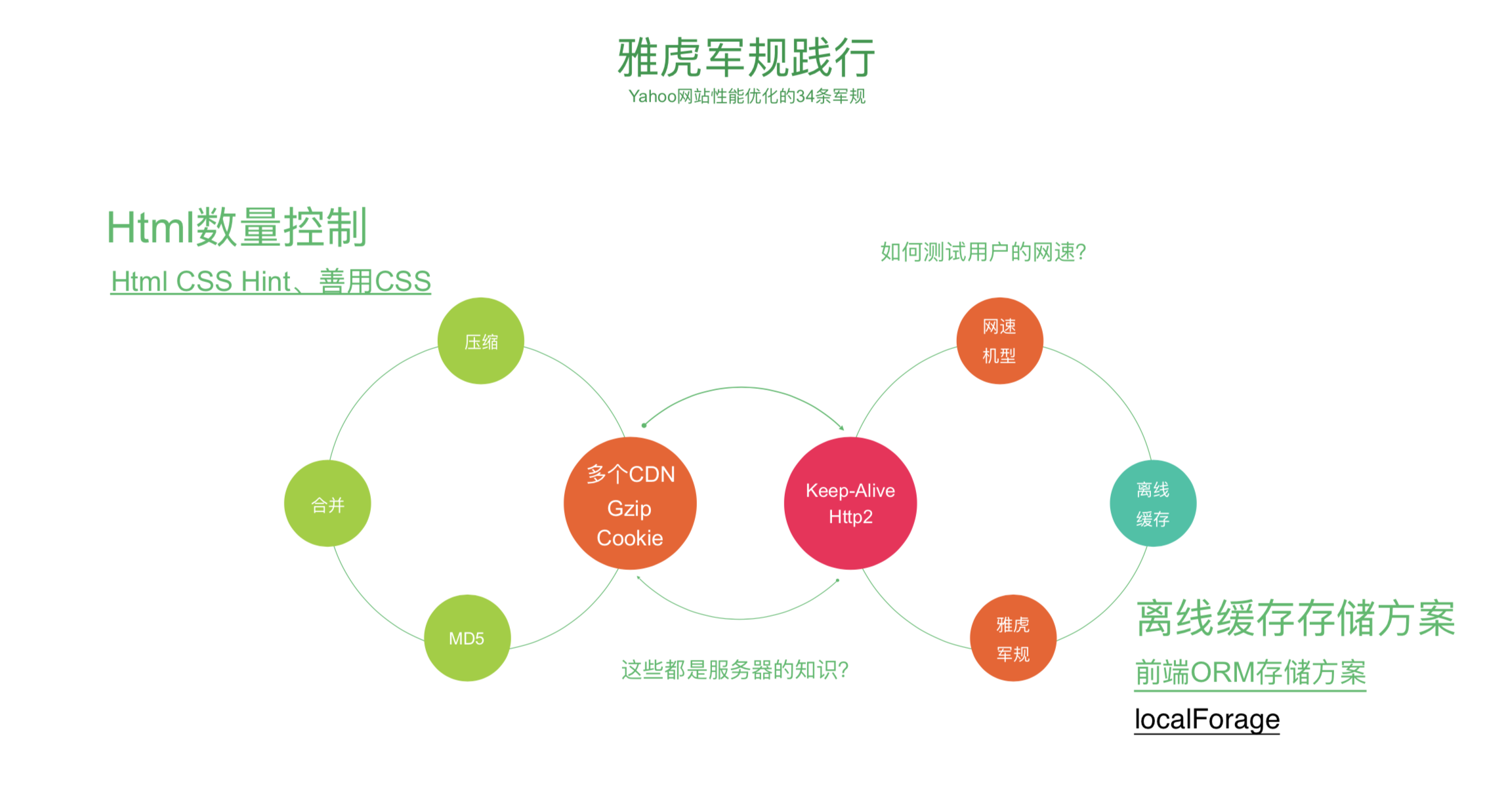
几个核心是:压缩 ,合并,md5
使用 HTML CSS HIND 对 HTML 的数量进行控制,HTML 数量如果多的话渲染的会比较慢,对 HTML 的数量进行严格把控,不能滥用 HTML
使用多个 CDN 的资源,多个 CDN 的优势:一般大型网站 Cookie 会非常的长,Cookie 比较烦的一点是每次请求会带去,然后后台 response 一个新的 Cookie,那么这个 Cookie 可能就会带来带去的,那么这么大的东西每次请求带来带去的会比较头痛,然而静态资源不需要 Cookie,那么就会使用到 CDN;那么这就是 CDN;CDN 的功能不仅仅是多资源很快的定位做缓存,并且可以节省 Cookie。
GZIP 的开启一般是 Nginx 中设置----》gzip:on
# 缓存优先级--服务器缓存策略

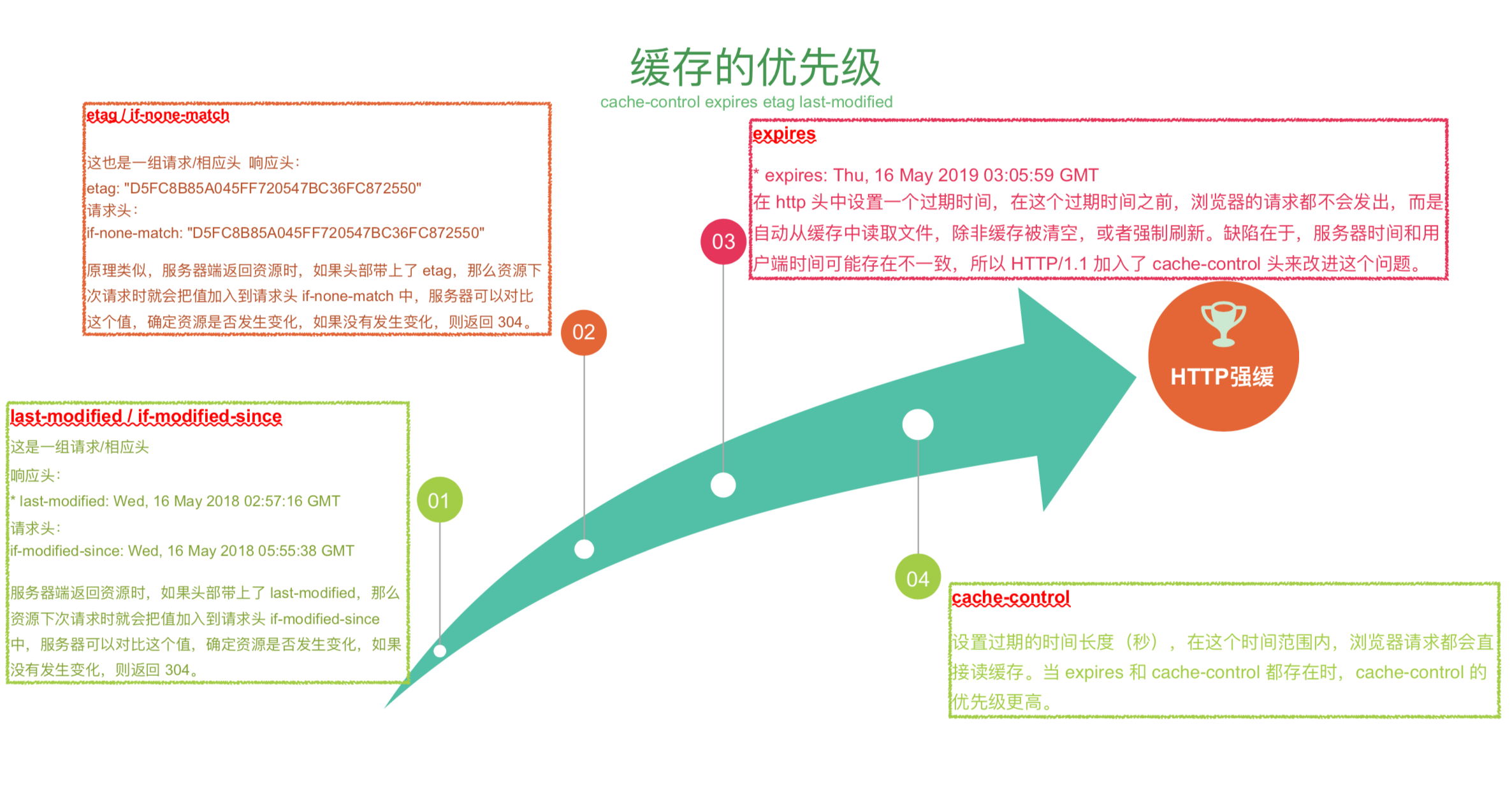
为什么会有这么多缓存:浏览器发展,http 的版本形态状态的设置。
优点:减少相应的延迟。减少网络带宽消耗。本地缓存不可控。
一般库文件才会使用 http 缓存,库文件一般不会频繁变动,所有一般是强缓
业务文件是一般是 etag 和离线缓存
# 离线缓存--localstorage 的使用
https://github.com/addyosmani/basket.js (opens new window)
1.首先使用 webpack-manifest-plugin,打印出 md5.js
例如
{
"a.js": "axx4.js",
"omega.js": "mods/omega.0987654321.js"
}
2
3
4
2.本地缓存去取 a.js
3.有激活 js addScript
3-1 a.js -> axx2.js 对比
3-2 更新流程 a.js -> axx4.js
3-3 删除 axx2.js
3-4 跳到下一步
4.没有
4-1 请求 axx4.js
4-1 axx4.js 放到缓存
# from memory cache 与 from disk cache
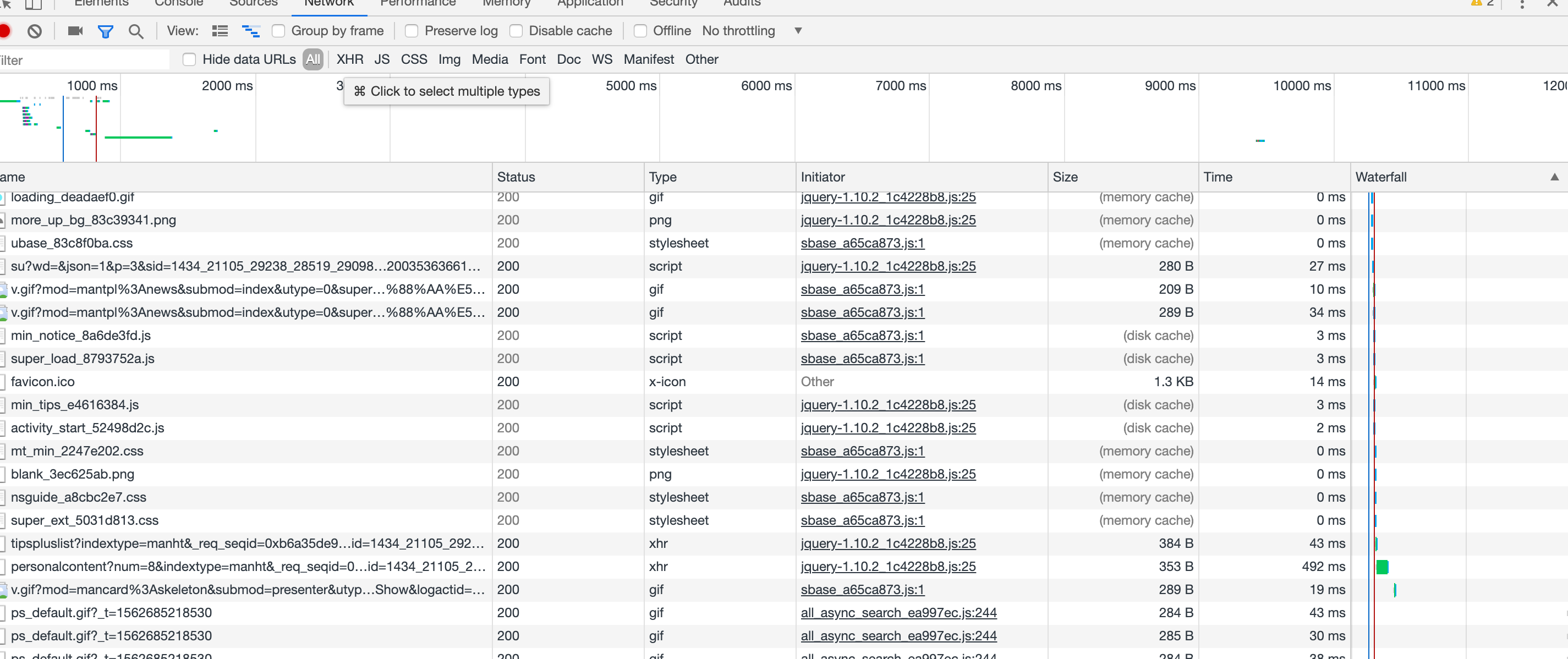
1.浏览器 Network 的 Size 栏
在浏览器开发者工具的 Network 的 Size 栏会出现的三种情况:
from memory cache
from disk cache
资源本身大小(比如:13.6K)
2.三级缓存原理
1)、先查找内存,如果内存中存在,从内存中加载;
2)、如果内存中未查找到,选择硬盘获取,如果硬盘中有,从硬盘中加载;
3)、如果硬盘中未查找到,那就进行网络请求;
4)、加载到的资源缓存到硬盘和内存;
3.区别
根据系统的配置环境分配 from memory cache 或 from disk cache
4.几种状态的执行顺序
现加载一种资源(例如:图片):
访问-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
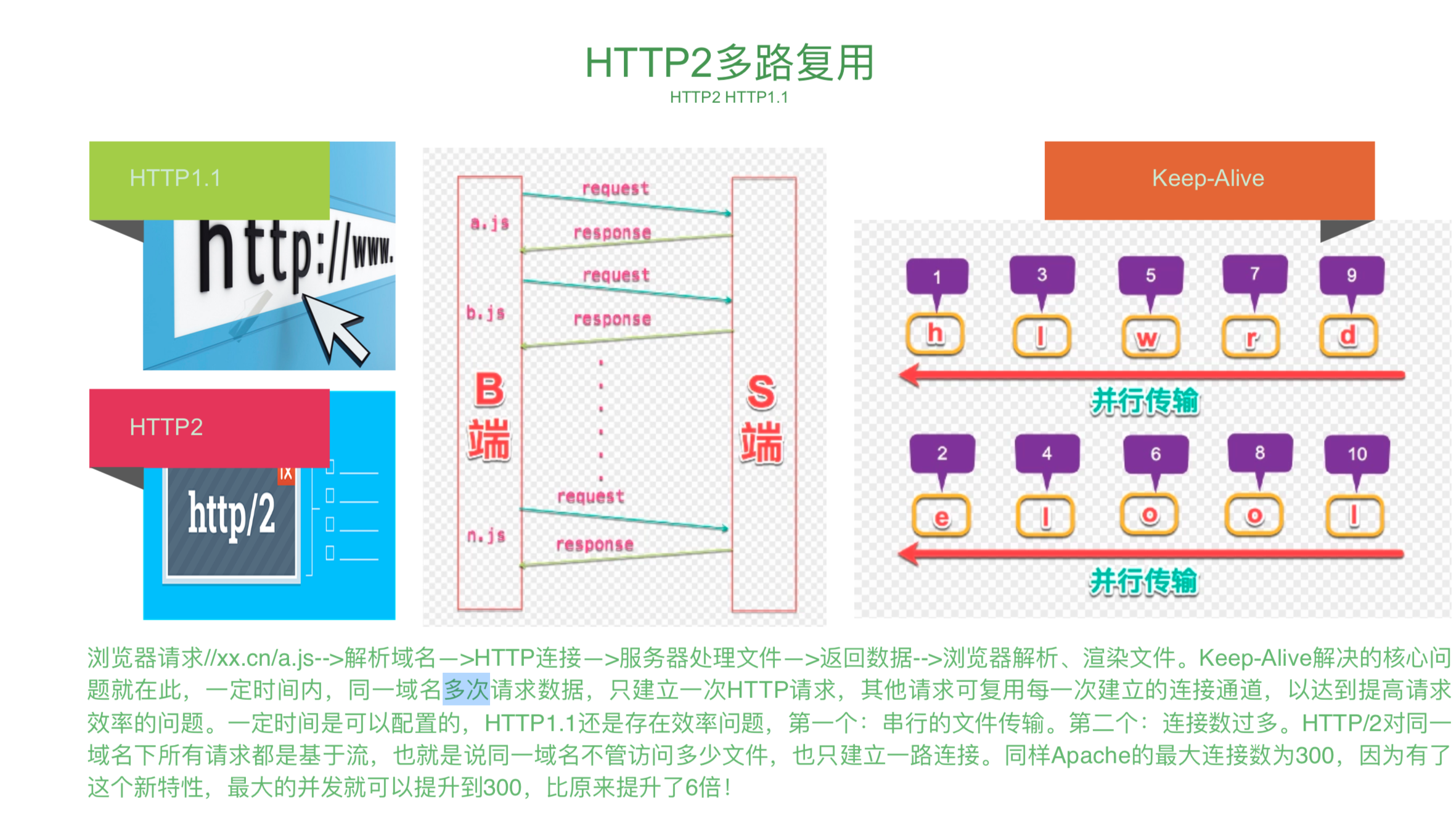
# http
http2 出现也就可以放弃打包压缩那一步了
# 渲染中性能优化
# 网页渲染流程
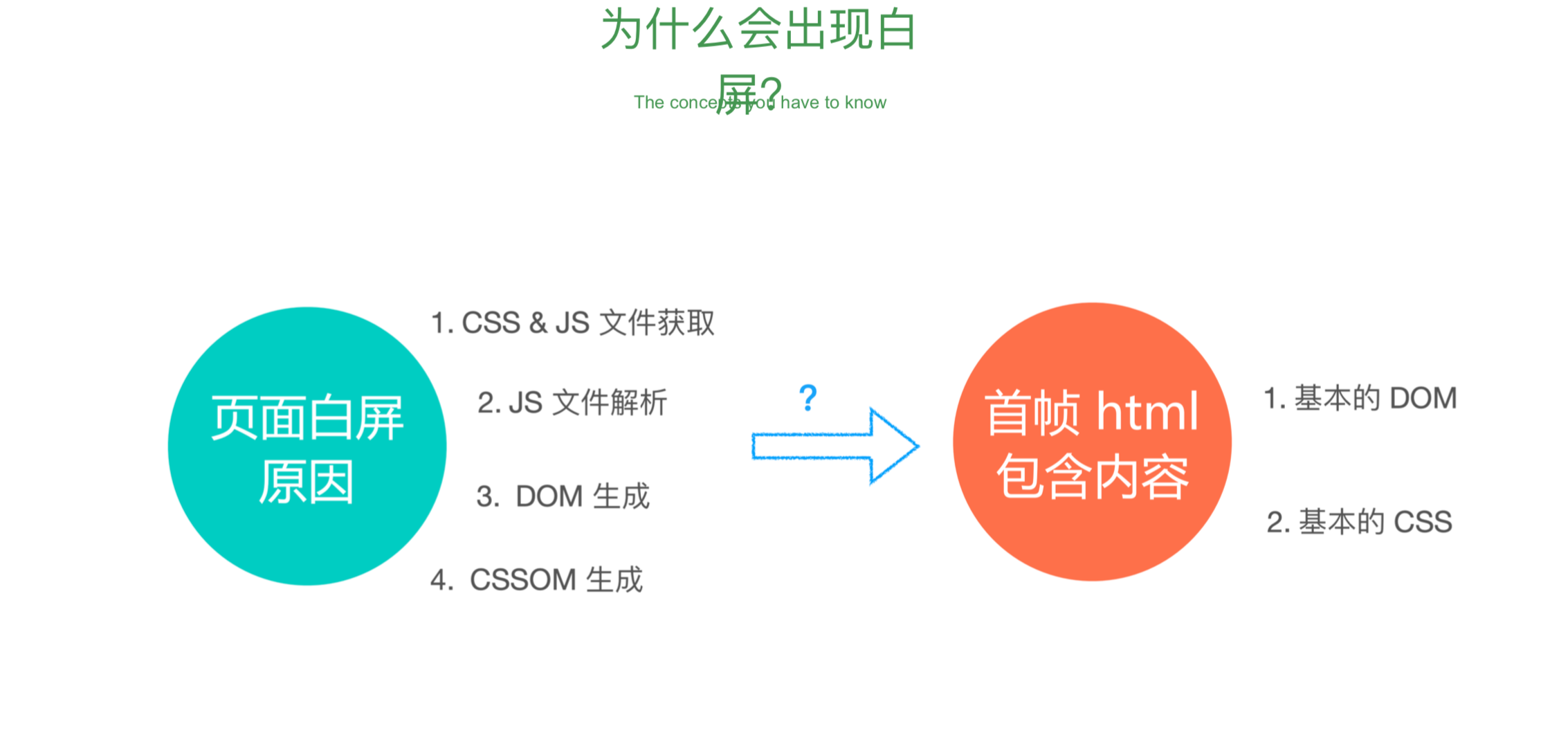
1-1.获取 dom 分割成多层 Parse HTML


1-2.对每个层计算样式结果 Recalculate Style
1-3 为每个节点生成图形和位置 重排 Layout
1-4 将每个节点绘制并填充到图层的位图中。重绘 Paint
1-5 绘制出来的纹理上传到 GPU Composite Layers
2 大致流程 Layout 、Paint 、Composite Layers
3 网页分层
根元素 position transform 半透明 滤镜 canvas video overflow
GPU 参与 参与好处:跨过 重排 重绘
CSS3d video webgl transform 滤镜
4.cpu gpu
相同点:两者总有总线和外界联系 ,有自己的缓存体系 以及数字和逻辑运算单元,为了完成计算任务而生的
不同点: cpu 主要负责操作系统和应用程序。而 gpu 负责和显示相关的 ,gpu 能干的活 cpu 都能干只不过效率低
5.有些属性读会造成重排
重绘不一定引起重排,重排一定会引起重绘。
会引起重排属性:offset scroll width height
建议 dom 读写分离 读:ele.height ele.offset
下一帧的时候再去设置相关的值 requestAnimationFrame requestIdleCallback(浏览器支持的不是很好)。60 帧 1000 毫秒内渲染出来
# ⻚页⾯面加载性能优化
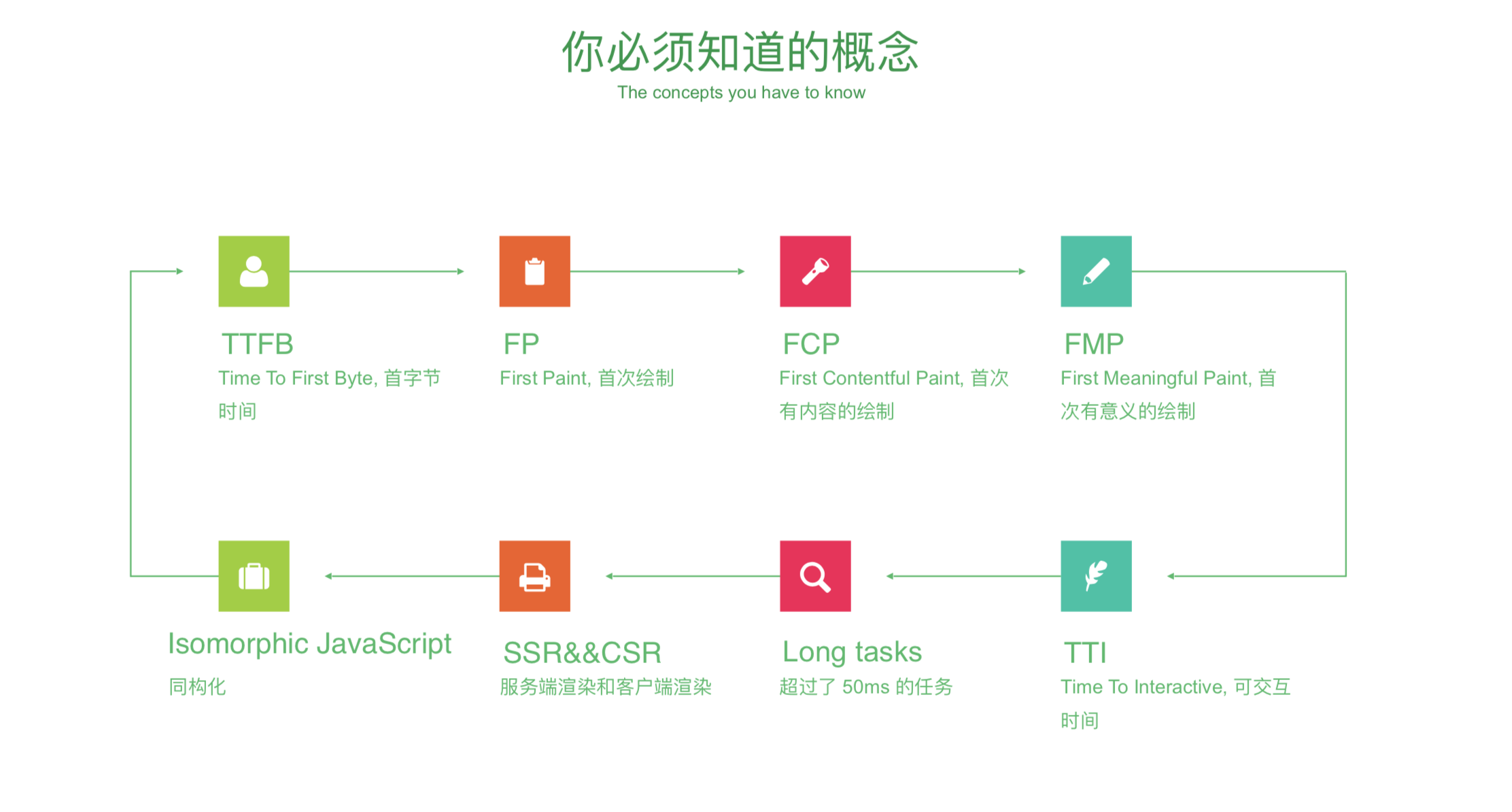
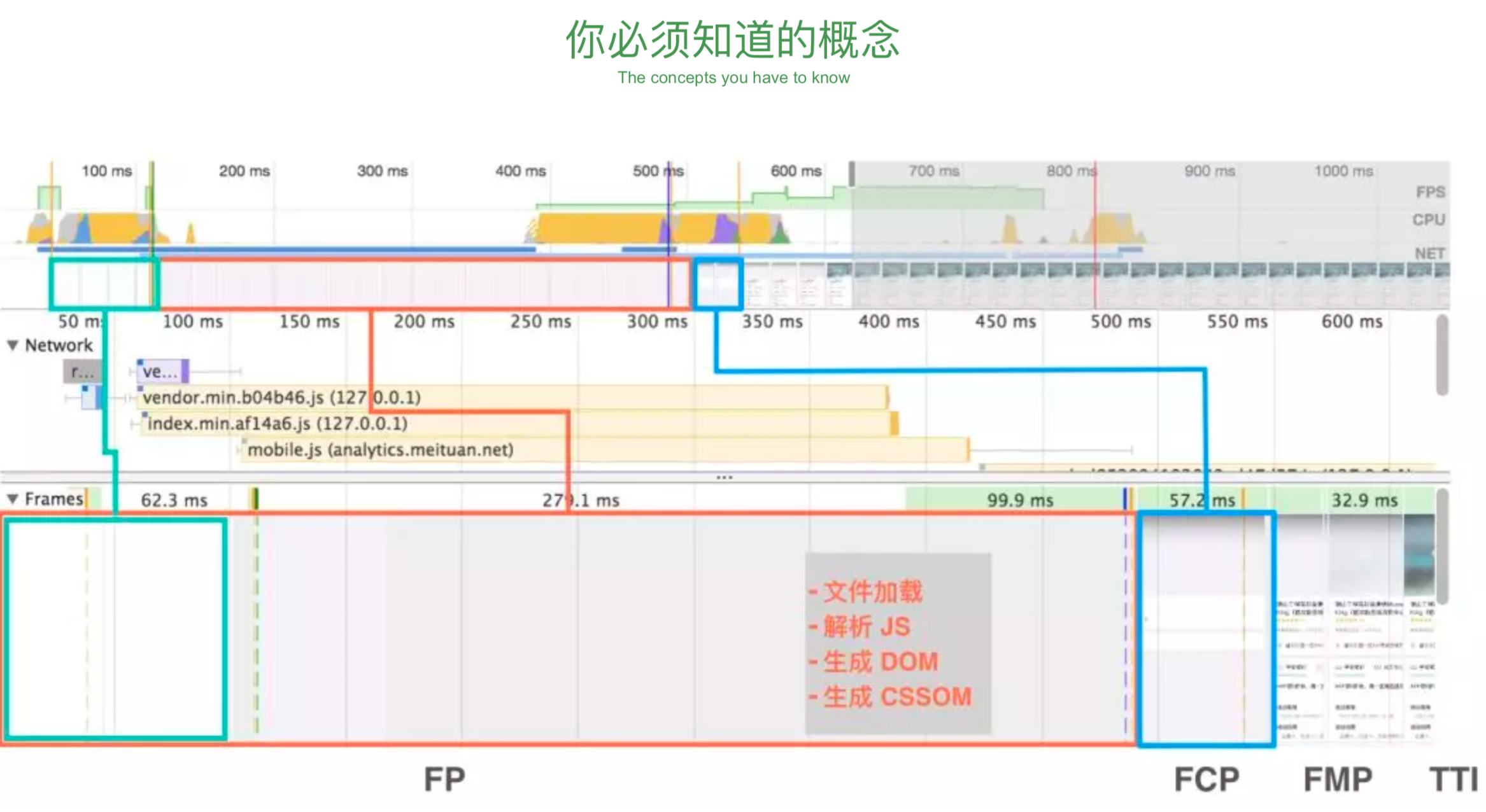
FP(First Paint) 首次绘制
FCP (First Contentful Paint), ⾸次 有内容的绘制
FMP (First Meaningful Pain) ⾸ 次有意义的绘制 没有绝对,自己决定
TTI (Time To Interactive), 可交互 时间 整个页面 ok

<div class="container">
<div class="ball" id="ball">ball</div>
</div>
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log(entry);
}
});
observer.observe({ entryTypes: ['paint'] })
2
3
4
5
6
7
8
9
10
11
PerformancePaintTiming {name: “first-paint”, entryType: “paint”, startTime: 16.30499999737367, duration: 0}
duration: 0
entryType: “paint”
FP
name: “first-paint”
startTime: 16.30499999737367
proto: PerformancePaintTiming
index.html:61
FCP
PerformancePaintTiming {name: “first-contentful-paint”, entryType: “paint”, startTime: 16.315000000759028, duration: 0}
duration: 0
entryType: “paint”
name: “first-contentful-paint”
startTime: 16.315000000759028
proto: PerformancePaintTiming
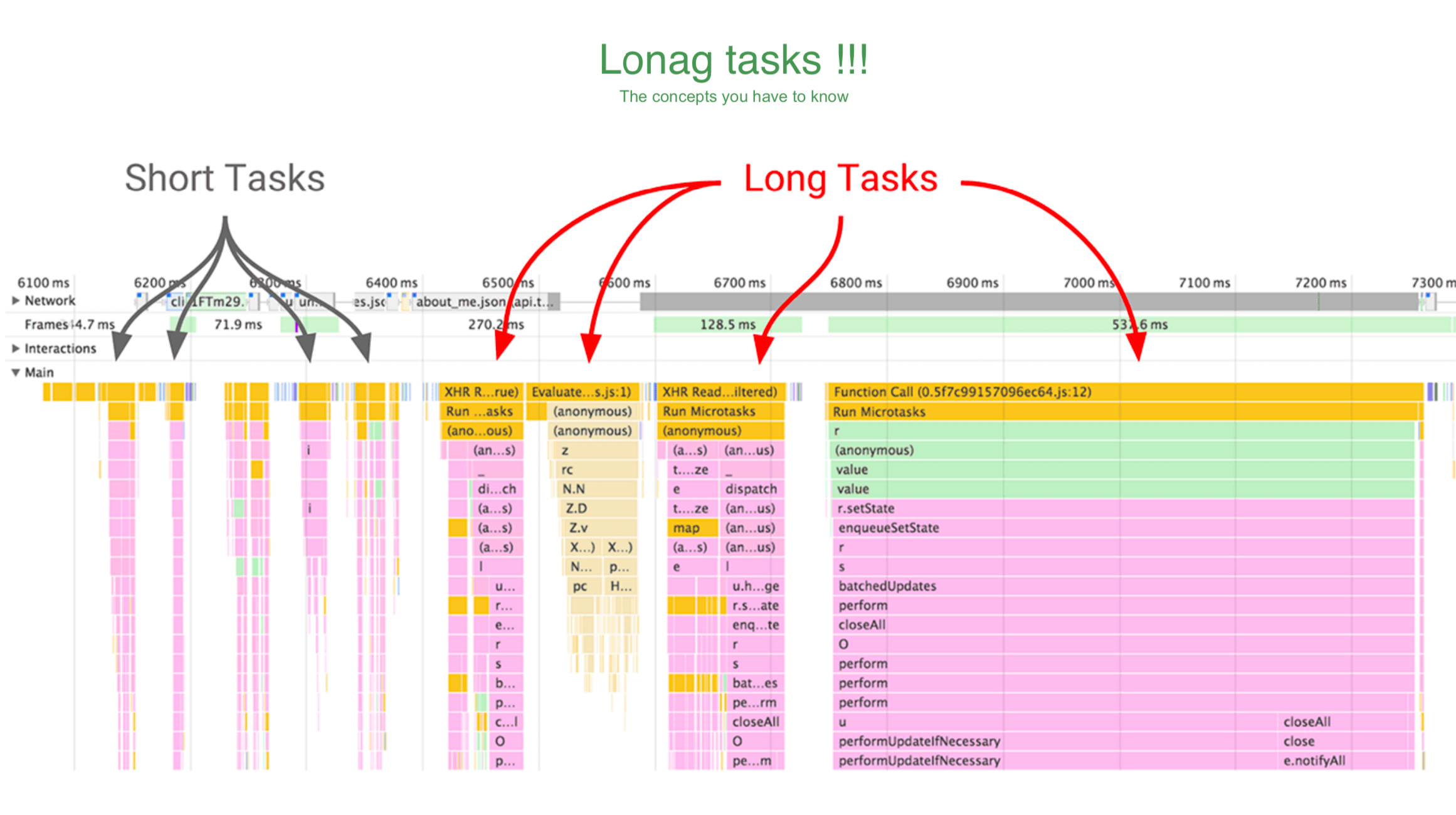 验证
验证
let arr = [];
for (let i = 0; i < 10000000; i++) {
arr.push(i)
}
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log(entry);
}
});
observer.observe({ entryTypes: ['longtask'] })
2
3
4
5
6
7
8
9
10
11
12
PerformanceLongTaskTiming {attribution: Array(1), name: “self”, entryType: “longtask”, startTime: 12.879999994765967, duration: 303.82500000996515}
attribution: [TaskAttributionTiming]
duration: 303.82500000996515
longtask
entryType: “longtask”
name: “self”
startTime: 12.879999994765967
proto: PerformanceLongTaskTiming