# JavaScript 函数式编程--上
# 函数式编程思维
# 范畴论 Category Theory
函数编程是范畴论的数学分支,是一门很复杂的数学学,认为世界上所有概念体系都可以抽象出一个个范畴 彼此之间存在某种关系概念、事物、对象等等,都构成范畴。
任何事物只要找出他们之间的关系,就能定义
"范畴就是使用箭头连接的物体。"(In mathematics, a category is an algebraic structure that comprises "objects" that are linked by "arrows". )
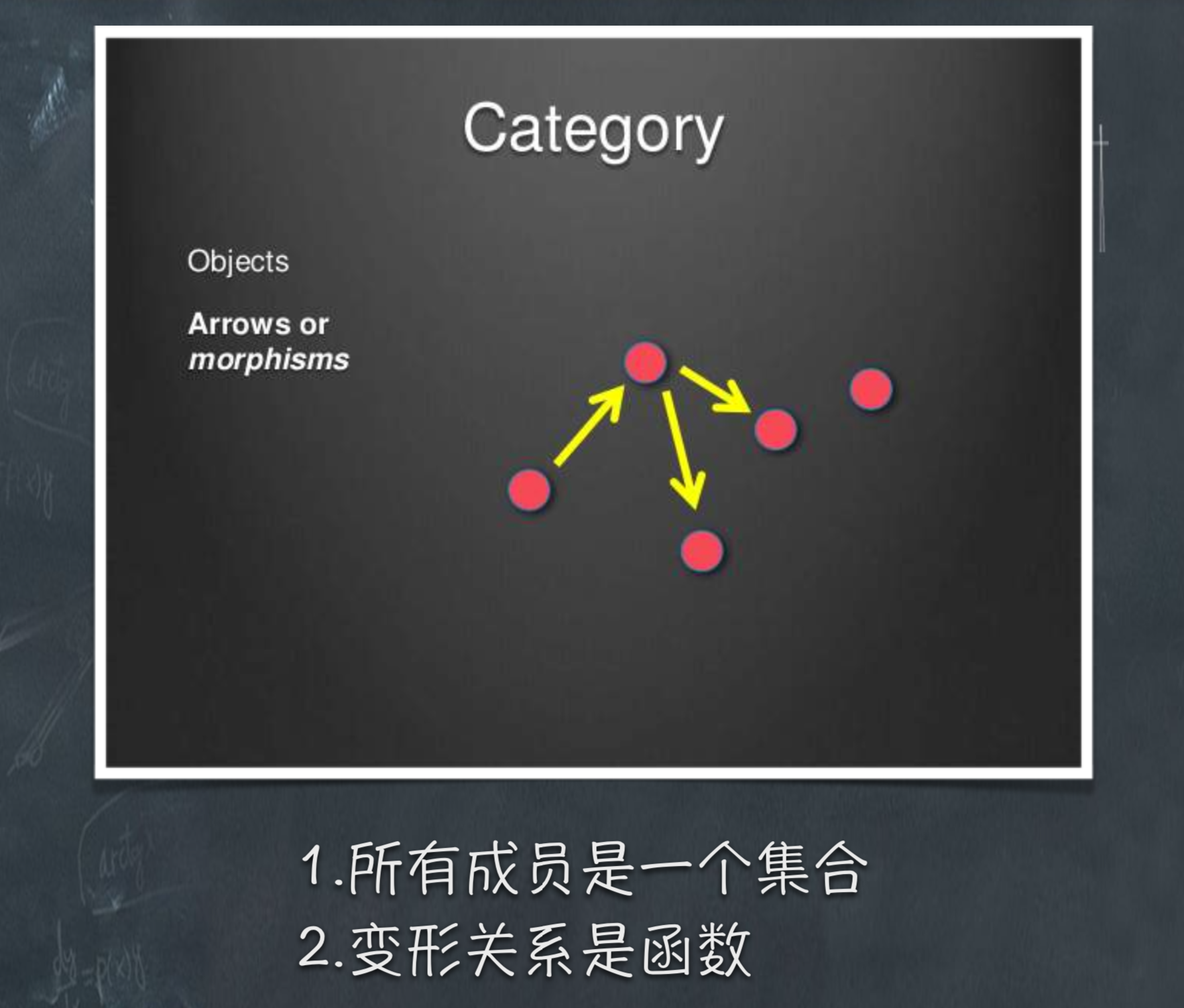
箭头表示范畴成员之间的关系,正式的名称叫做"态射" (morphism)。范畴论认为,同一个范畴的所有成员, 就是不同状态的"变形"(transformation)。通过"态射", 一个成员可以变形成另一个成员。
# 数学模型
既然"范畴"是满足某种变形关系的所有对象,就可以总结出它的数学模型。
所有成员是一个集合
变形关系是函数
2
3
也就是说,范畴论是集合论更上层的抽象,简单的理解就是"集合 + 函数"。
理论上通过函数,就可以从范畴的一个成员,算出其他所有成员
# 范畴与容器
我们可以把"范畴"想象成是一个容器,里面包含两样东西。
值(value)
值的变形关系,也就是函数。
2
3
下面我们使用代码,定义一个简单的范畴。
class Category {
constructor(val) {
this.val = val;
}
addOne(x) {
return x + 1;
}
}
2
3
4
5
6
7
8
9
10
上面代码中,Category 是一个类,也是一个容器,里面包含一个值(this.val)和一种变形关系(addOne)。你可能已经看出来了,这里的范畴,就是所有彼此之间相差 1 的数字。
# 范畴论与函数式编程的关系
范畴论使用函数,表达范畴之间的关系。
伴随着范畴论的发展,就发展出一整套函数的运算方法。这套方法起初只用于数学运算,后来有人将它在计算机上实现了,就变成了今天的"函数式编程"。
# 本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是碰巧它能用来写程序
所以,你明白了吗,为什么函数式编程要求函数必须是纯的,不能有副作用?因为它是一种数学运算,原始目的就是求值,不做其他事情,否则就无法满足函数运算法则了。
总之,在函数式编程中,函数就是一个管道(pipe)。这头进去一个值,那头就会出来一个新的值,没有其他作用。
# 函数式编程基础理论
1.函数式编程(Functional Programming)其实相对于计算机的历史而 言是一个非常古老的概念,甚至早于第一台计算机的诞生。函数式 编程的基础模型来源于 λ (Lambda x=>x*2)演算,而 λ 演算并非设计 于在计算机上执行,它是在 20 世纪三十年代引入的一套用于研究 函数定义、函数应用和递归的形式系统。
2.函数式编程不是用函数来编程,也不是传统的面向过程编程。主 旨在于将复杂的函数符合成简单的函数(计算理论,或者递归论, 或者拉姆达演算)。运算过程尽量写成一系列嵌套的函数调用
3.JavaScript 是披着 C 外衣的 Lisp。
4.真正的火热是随着 React 的高阶函数而逐步升温
# 函数式编程特点
- 函数是”第一等公民”
- 只用”表达式",不用"语句"
- 没有”副作用"
- 不修改状态
- 引用透明(函数运行只靠参数)
# 函数式编程常用的核心概念
# 纯函数
# 再次强调“纯”
首先,我们要厘清纯函数的概念。
纯函数是这样一种函数,即相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用。
2
比如 slice 和 splice,这两个函数的作用并无二致——但是注意,它们各自的方式却大不同,但不管怎么说作用还是一样的。我们说 slice 符合纯函数的定义是因为对相同的输入它保证能返回相同的输出。而 splice 却会嚼烂调用它的那个数组,然后再吐出来;这就会产生可观察到的副作用,即这个数组永久地改变了
var xs = [1,2,3,4,5];
// 纯的
xs.slice(0,3);
//=> [1,2,3]
xs.slice(0,3);
//=> [1,2,3]
xs.slice(0,3);
//=> [1,2,3]
// 不纯的
xs.splice(0,3);
//=> [1,2,3]
xs.splice(0,3);
//=> [4,5]
xs.splice(0,3);
//=> []
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在函数式编程中,我们讨厌这种会改变数据的笨函数。我们追求的是那种可靠的,每次都能返回同样结果的函数,而不是像 splice 这样每次调用后都把数据弄得一团糟的函数,这不是我们想要的。
来看看另一个例子。
// 不纯的
var minimum = 21;
var checkAge = function(age) {
return age >= minimum;
};
// 纯的
var checkAge = function(age) {
var minimum = 21;
return age >= minimum;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
在不纯的版本中,checkAge 的结果将取决于 minimum 这个可变变量的值。换句话说,它取决于系统状态(system state);这一点令人沮丧,因为它引入了外部的环境,从而增加了认知负荷(cognitive load)。
这个例子可能还不是那么明显,但这种依赖状态是影响系统复杂度的罪魁祸首(http://www.curtclifton.net/storage/papers/MoseleyMarks06a.pdf ) (opens new window)。输入值之外的因素能够左右 checkAge 的返回值,不仅让它变得不纯,而且导致每次我们思考整个软件的时候都痛苦不堪。
另一方面,使用纯函数的形式,函数就能做到自给自足。我们也可以让 minimum 成为一个不可变(immutable)对象,这样就能保留纯粹性,因为状态不会有变化。要实现这个效果,必须得创建一个对象,然后调用 Object.freeze 方法:
var immutableState = Object.freeze({
minimum: 21
});
2
3
# 副作用可能包括
让我们来仔细研究一下“副作用”以便加深理解。那么,我们在纯函数定义中提到的万分邪恶的副作用到底是什么?“作用”我们可以理解为一切除结果计算之外发生的事情。
“作用”本身并没什么坏处。“副作用”的关键部分在于“副”。就像一潭死水中的“水”本身并不是幼虫的培养器,“死”才是生成虫群的原因。同理,副作用中的“副”是滋生 bug 的温床。
副作用是在计算结果的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。
副作用可能包含,但不限于:
更改文件系统
往数据库插入记录
发送一个 http 请求
可变数据
打印/log
获取用户输入
DOM 查询
访问系统状态
这个列表还可以继续写下去。概括来讲,只要是跟函数外部环境发生的交互就都是副作用——这一点可能会让你怀疑无副作用编程的可行性。函数式编程的哲学就是假定副作用是造成不正当行为的主要原因。 这并不是说,要禁止使用一切副作用,而是说,要让它们在可控的范围内发生。后面讲到 functor 和 monad 的时候我们会学习如何控制它们,目前还是尽量远离这些阴险的函数为好。 副作用让一个函数变得不纯是有道理的:从定义上来说,纯函数必须要能够根据相同的输入返回相同的输出;如果函数需要跟外部事物打交道,那么就无法保证这一点了。 我们来仔细了解下为何要坚持这种「相同输入得到相同输出」原则。注意,我们要复习一些八年级数学知识了。
# 八年级数学
根据 mathisfun.com:
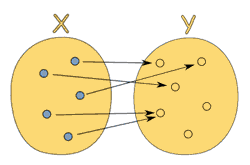
函数是不同数值之间的特殊关系:每一个输入值返回且只返回一个输出值。
2
换句话说,函数只是两种数值之间的关系:输入和输出。尽管每个输入都只会有一个输出,但不同的输入却可以有相同的输出。下图展示了一个合法的从 x 到 y 的函数关系;
https://www.shuxuele.com/sets/function.html (opens new window)
相反,下面这张图表展示的就不是一种函数关系,因为输入值 5 指向了多个输出:
https://www.shuxuele.com/sets/function.html (opens new window)
函数可以描述为一个集合,这个集合里的内容是 (输入, 输出) 对:[(1,2), (3,6), (5,10)](看起来这个函数是把输入值加倍)。
如果输入直接指明了输出,那么就没有必要再实现具体的细节了。因为函数仅仅只是输入到输出的映射而已,所以简单地写一个对象就能“运行”它,使用 [] 代替 () 即可。
var toLowerCase = {"A":"a", "B": "b", "C": "c", "D": "d", "E": "e", "D": "d"};
toLowerCase["C"];
//=> "c"
var isPrime = {1:false, 2: true, 3: true, 4: false, 5: true, 6:false};
isPrime[3];
//=> true
2
3
4
5
6
7
8
9
当然了,实际情况中你可能需要进行一些计算而不是手动指定各项值;不过上例倒是表明了另外一种思考函数的方式。(你可能会想“要是函数有多个参数呢?”。的确,这种情况表明了以数学方式思考问题的一点点不便。暂时我们可以把它们打包放到数组里,或者把 arguments 对象看成是输入。等学习 curry 的概念之后,你就知道如何直接为函数在数学上的定义建模了。)
戏剧性的是:纯函数就是数学上的函数,而且是函数式编程的全部。使用这些纯函数编程能够带来大量的好处,让我们来看一下为何要不遗余力地保留函数的纯粹性的原因。
# 追求“纯”的理由
纯函数不仅可以有效降低系统的复 杂度,还有很多很棒的特性,比如 可缓存性
import _ from 'lodash';
var sin = _.memorize(x => Math.sin(x));
//第一次计算的时候会稍慢一点 var a = sin(1);
//第二次有了缓存,速度极快
var b = sin(1);
2
3
4
5
6
# 函数式编程-幂等性
执行多次所产生的影响均与一次执行的影响相同,也就是说执行一次和执行多次对系统内部的状态影响是一样的
class Person {
constructor () {
this.name = name;
},
sayName () {
console.log(my name is + this.name);
}
}
var person = new Person(zhangsan)
person.sayName();
person.sayName();
2
3
4
5
6
7
8
9
10
11
12
13
# 纯函数和幂等性的区别
1.法调用多次对内部的状态影响是一样的,则这么方法就具有幂等性,在函数式编程中,纯函数也具有幂等性,但具有幂等性的函数却不一定是纯函数。
2.纯函数主要强调相同的输入,多次调用,输出也相同且无副作用,而幂等主要强调多次调用,对内部的状态的影响是一样的,调用返回值可能不同。
# 总结
我们已经了解什么是纯函数了,也看到作为函数式程序员的我们,为何深信纯函数是不同凡响的。从这开始,我们将尽力以纯函数式的方式书写所有的函数。为此我们将需要一些额外的工具来达成目标,同时也尽量把非纯函数从纯函数代码中分离。
如果手头没有一些工具,那么纯函数程序写起来就有点费力。我们不得不玩杂耍似的通过到处传递参数来操作数据,而且还被禁止使用状态,更别说“作用”了。没有人愿意这样自虐。所以让我们来学习一个叫 curry 的新工具。
# 函数的柯里化
# 偏应用函数
在讲函数柯里化之前先讲偏应用函数(偏函数),函数柯里化主要是通过偏应用函数的实现,把接受多个参数的函数变换成接受一个单一参数的函数,并且返回接受余下的参数而且返回结果的新函数
const partial = (f, ...args) =>
(...moreArgs) => f(...args, ...moreArgs)
const add3 = (a, b, c) => a + b + c
// 偏应用 `2` 和 `3` 到 `add3` 给你一个单参数的函数 const fivePlus = partial(add3, 2, 3)
fivePlus(4)
//bind实现
const add1More = add3.bind(null,2,3) // (c) => 2 + 3 + c
2
3
4
5
6
7
8
9
总结
通过上面程序了解到柯里化函数的特点是总是返回一个一元的函数:一个带有一个参数的新函数,不同的是普通函数可以根据需要一次获取尽可能多的参数
# 函数的柯里化
# 为什么要柯里化
1.柯里化在函数组合的上下文中起到关键的作用,能够让你重新组合你的应用,将复杂的功能拆分成一个个简单的部分,这样容易更改,理解
2.柯里化也是一种函数预加载的方法,通过传递较少的参数得到一个在相同词法作用域当中缓存了这些参数的新函数,其实这也是一种对参数的缓存
import { curry } from 'lodash';
var match = curry((reg, str) => str.match(reg));
var filter = curry((f, arr) => arr.filter(f));
var haveSpace = match(/\s+/g); //haveSpace(“ffffffff”);
//haveSpace(“a b");
//filter(haveSpace, ["abcdefg", "Hello World"]); filter(haveSpace)(["abcdefg", "Hello World"])
2
3
4
5
6
7
8
9
10
# 柯里化函数的应用场景
1.延迟计算
// 普通实现
var sum = function(args){
return args.reduce(function(a,b){
return a+b
});
};
var result = sum([1,2,3,4,5]); // 15
// 柯里化实现
function add() {
var _args = [].slice.call(arguments);
var adder = function () {
// 利用闭包特性保存_args的值
var _adder = function() {
[].push.apply(_args, [].slice.call(arguments));
return _adder;
};
// 利用隐式转换的特性,计算最终的值返回
_adder.toString = function () {
return _args.reduce(function (a, b) {
return a + b;
});
}
return _adder;
}
return adder.apply(null, [].slice.call(arguments));
}
var sum = add();
sum(1,2,3)(4);
sum(5);
sum() // 15
优点:调用灵活,参数定义随意
充分利用了柯里化提延迟执行的特点
延迟执行 – 返回新函数可以进行任意调用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2.DOM 操作中的事件绑定(动态创建函数) 当在多次调用同一个函数,并且传递的参数绝大多数是相同的。
// 普通版本
var addEvent = function(el, type, fn, capture) {
if (window.addEventListener) {
el.addEventListener(type, function(e) {
fn.call(el, e);
}, capture);
} else if (window.attachEvent) {
el.attachEvent("on" + type, function(e) {
fn.call(el, e);
});
}
};
// 柯里化版本
var addEvent = (function(){
if (window.addEventListener) {
return function(el, type, fn, capture) {
el.addEventListener(type, function(e) {
fn.call(el, e);
}, (capture));
};
} else if (window.attachEvent) {
return function(el, type, fn, capture) {
el.attachEvent("on" + type, function(e) {
fn.call(el, e);
});
};
}
})();
优点:不用每次调用进行 if () {}else {} 判断兼容性问题
充分利用了柯里化提前返回和延迟执行的特点
提前返回 – 使用函数立即调用进行了一次兼容判断(部分求值),返回兼容的事件绑定方法
延迟执行 – 返回新函数,在新函数调用兼容的事件方法。等待addEvent新函数调用,延迟执行
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
当然应用场景还有很多,比如我们经常提到的防抖和节流问题,充分的利用了函数式编程的延迟执行特性,将多个间隔接近的函数执行合并成一次函数执行来提高性能问题。 关于事件节流和防抖动将会在后续的专题中单独指出
# 总结
curry 函数用起来非常得心应手,每天使用它对我来说简直就是一种享受。它堪称手头必备工具,能够让函数式编程不那么繁琐和沉闷。 通过简单地传递几个参数,就能动态创建实用的新函数;而且还能带来一个额外好处,那就是保留了数学的函数定义,尽管参数不止一个。 下一章我们将学习另一个重要的工具:组合(compose)。
# 函数的组合
纯函数以及如何把它柯里化写出的洋葱代码 h(g(f(x))),为了解决函数嵌套问题,我们需要用到函数的组合
const compose = (f, g) => (x => f(g(x)));
var first = arr => arr[0];
var reverse = arr => arr.reverse();
var last = compose(first, reverse);
last([1,2,3,4,5]);
2
3
4
5
# Point Free
把对象自带的方法转化成纯函数,不要命名转瞬即逝的中间变量。
这个函数中,我们使用了 str 作为我们的中间变量,但 这个中间变量除了让代码变得长了一点以外是毫无意义 的。
const f = str => str.toUpperCase().split(' ')
优缺点
const compose = (f, g) => (x => f(g(x)));
var toUpperCase = word => word.toUpperCase();
var split = x => (str => str.split(x));
var f = compose(split(' '), toUpperCase);
f("abcd efgh");
2
3
4
5
6
这种风格能够帮助我们减少不必要的命名,让代码保持简洁和通用。
# 声明式与命令式代码
let CEOs = [];
for(var i = 0; i < companies.length; i++){
CEOs.push(companies[i].CEO)
}
//声明式
let CEOs = companies.map(c => c.CEO);
2
3
4
5
6
# 惰性求值、惰性函数、惰性链
在指令式语言中以下代码会按顺序执行,由于每个函数都有可能改动或者依赖于其外部的状态,因此必须顺序执行。(大白话利用重写函数)
# 高阶函数
函数当参数,把传入的函数做一个封装,然后返回这个封装函数,达到更高程度的抽象
举个简单的例子:
function math(fn,array){
return fn(array[0],array[1])
}
var add = function(a,b){
return a+b
}
console.log(math(add,[1,2]))
2
3
4
5
6
7
8
9
# 特点
function math(fn,array){
return fn(array[0],array[1])
}
var add = function(a,b){
return a+b
}
console.log(math(add,[1,2]))
2
3
4
5
6
7
8
# 尾调用优化
指函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。函数调用自身,称为递归。
如果尾调用自身,就称为尾递归。递归需要保存大量的调用记录,很容易发生栈溢出错误,如果使用尾递归优化,将递归变为循环,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
例如:
//斐波那契数列
function factorial(n){
if(n===1) return 1
return n*factorial(n-1)
}
//执行过程如下
// 5*factorial(4)
// 4*factorial(3)
// 3*factorial(2)
// 2*factorial(1)
// 2*1
// 3*2
// 4*6
// 5**24
factorial(5)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
如果 console.log(factorial(1000000))会出现,浏览器超过了最大调用堆栈大小,如图:
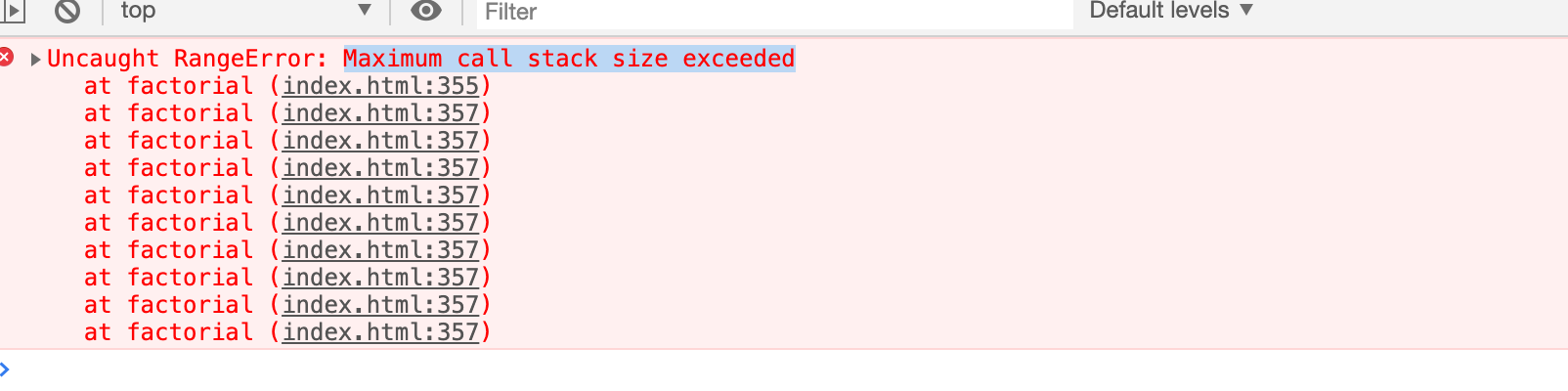
普通递归时,内存需要记录调用的堆栈所出的深度和位置信息。在最底层计算返回值,再根据记录的信息,跳回上一层级计算,然后再跳回更高一层,依次运行,直到最外层的调用函数。在 cpu 计算和内存会消耗多,而且当深度过大时,会出现堆栈溢出。
ES6 强制使用尾递归
function factorial(n,total){
if(n===1) return total
return n*factorial(n-1,total)
}
factorial(5,1)
//执行过程如下
//factorial(4,5)
// factorial(3,20)
// factorial(2,60)
// factorial(1,120)
// 120
2
3
4
5
6
7
8
9
10
11
# 进一步加深理解
再举一个简单的例子
function sum(n){
if(n===1) return 1
return n+sum(n-1)
}
console.log(sum(5))
(5 + sum(4))
(5 + (4 + sum(3)))
(5 + (4 + (3 + sum(2))))
(5 + (4 + (3 + (2 + sum(1))))) (5 + (4 + (3 + (2 + 1))))
(5 + (4 + (3 + 3)))
(5 + (4 + 6))
(5 + 10)
15
}
// sum(5)
// (5 + sum(4))
// (5 + (4 + sum(3)))
// (5 + (4 + (3 + sum(2))))
// (5 + (4 + (3 + (2 + sum(1))))) (5 + (4 + (3 + (2 + 1))))
// (5 + (4 + (3 + 3)))
// (5 + (4 + 6))
// (5 + 10)
// 15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 死循环与爆栈不是一个意思:栈的递归是内存用完了,死循环是 ui 的主线程没有能力执行其他的代码了。爆栈是内存被用光了,死循环也会被内存用光,但是 js 是单线程的,死循环不能执行其他代码
细数尾递归
function sum(x, total) {
if (x === 1) {
return x + total;
}
return sum(x - 1, x + total);
},
// sum(5, 0)
// sum(4, 5)
// sum(3, 9)
// sum(2, 12)
// sum(1, 14)
// 15
2
3
4
5
6
7
8
9
10
11
12
正个计算过程是线性的,调用一次 sum(x, total)后,会进入下一个栈,相关的数据信息和 跟随进入,不再放在堆栈上保存。当计算完最后的值之后,直接返回到最上层的 sum(5,0)。这能有效的防止堆栈溢出。在 ECMAScript 6,我们将迎来尾递归优化,通过尾递归优化,javascript 代码在解释成机器 码的时候,将会向 while 看起,也就是说,同时拥有数学表达能力和 while 的效能。
###接下了来先搞清一个概念 1.浏览器并没有实现尾递归,开启须强制
function foo(n) {
return bar(n*2);
}
function bar() {
//查看调用帧
console.trace();
}
foo(1);
2
3
4
5
6
7
8
9
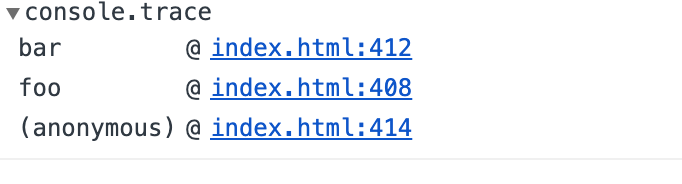 上述代码的目标只有一个执行栈
上述代码的目标只有一个执行栈
//强制指定,只留下bar
return continue
!return
#function()
2
3
4
2.【最后一步】是否调用自身,而不是是否在【最后一行】调用自身
3.最后一行调用其他函数,并返回叫尾调用
function init(){
test(i)
}
function test(i){
init(i-1)
}
2
3
4
5
6
4.尾递归有两种一种浏览器实现的,一种自己写的
5.能用 while 解决的都用 while,因为 while 是线性的
# 闭包
大白话理解:拿到你不应该拿到的东西,为什么这么说,本来这个东西不是你的但是在函数的私有的内部,但想取到,就用到了闭包。
小黄书的说法:保留了当前的函数执行的词法作用域,把词法作用域拿出去
红皮书的书法:有权访问其他函数内部变量的的函数