# 前端性能优化必备服务器知识
# 浏览器渲染过程
https://www.w3.org/TR/navigation-timing/ (opens new window)

地址栏中输入 url,敲回车--》浏览器解决网络问题,是否能够出外网(测试从内网跨越到外网去,这个障碍可能是路由器、网关等等)----》解析域名,输入的网址是一段字符串,计算机不识别,必须通过 DNS 服务器做一下 DNS 域名解析。(DNS 就是一个大型数据库,在这个数据库中就维护着域名和 ip 地址的映射关系),返回 ip 地址,计算机就能够识别服务器在什么地方---》TCP 连接之后把数据发过去,发到服务器上---〉到了服务器上,服务器入口就是一个 IP,IP 后面有好多服务器,好多服务器会共用一个 IP(怎么做到这一点,会用到反向代理)----》通过反向代理,服务器进行请求。----〉通过 TCP 响应响应就会渲染,那么就会进入该主题
缓存层:promptfor unload、redirect、Appcache
网络层:DNS、TCP、Request、Response
渲染层:Processing、onload
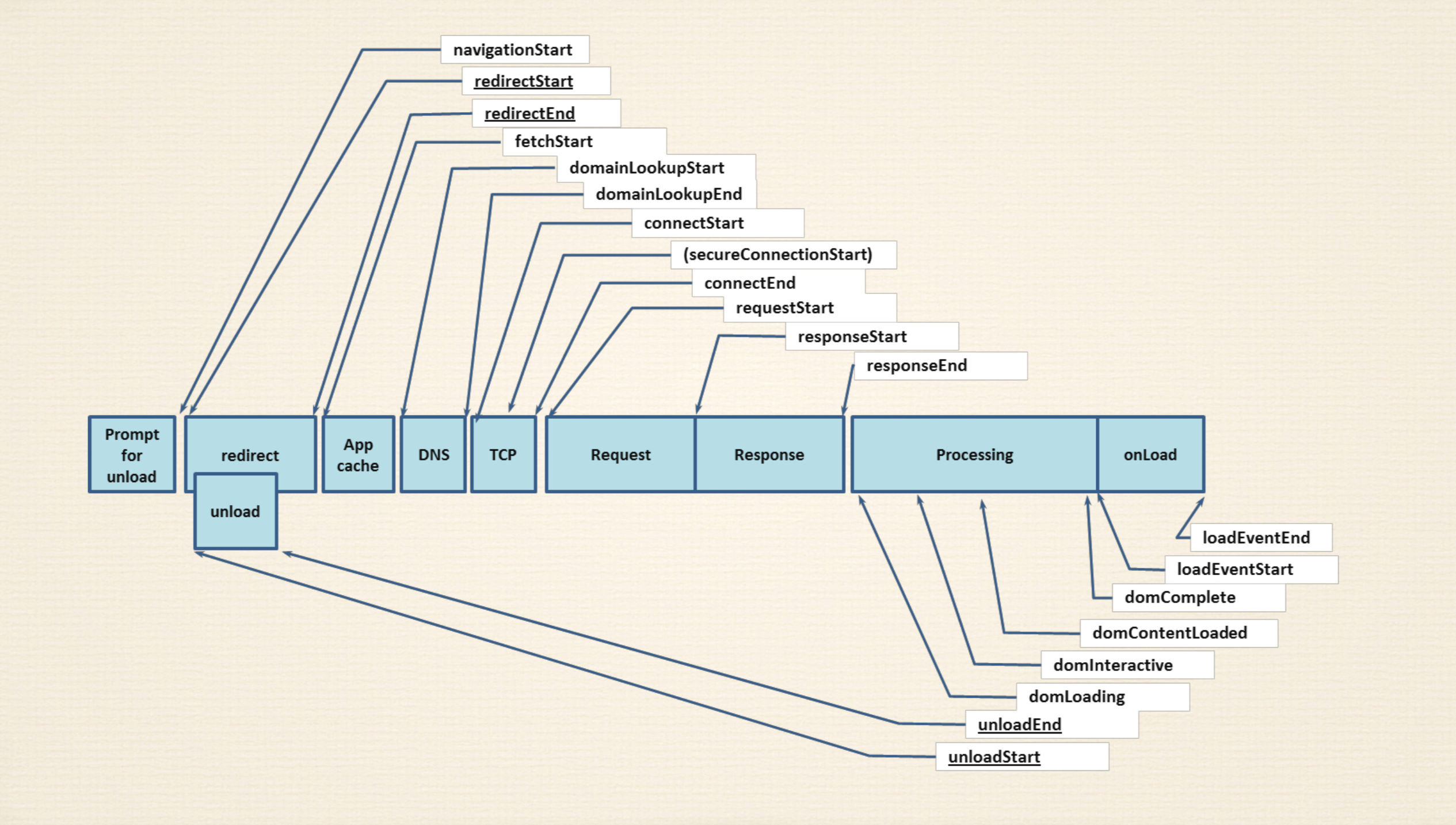
unload 是指卸载掉了上一个页面,与重定向是并发的。
redirect 在浏览器缓存中寻找,缓存以索引形式存在。找到页面是否下载过,并且判断文件是否支持脱机浏览。(很早之前浏览器支持脱机浏览)前提文件没有过期
DNS 部分的优化使用 CDN
Http 是基于 Tcp 和 Udp,Tcp 是 IO 传输,每次请求都要握手挥手,所以可以优化,复用连接。
TCP 部分优化由底层程序员处理 HTTP1、2、3 长连接
TCP secureConnection 安全连接时间 https 基于 SSL 连接所以时间比较长
Requset->Resopnse 之前考虑服务器的性能数据质量等等
Resoponse 部分就是压缩 文件类型(text img 等速度是不一样的)和压缩之前的权衡
Processing domloading 先把 dom 加载都内存里 domInteractive 生成 dom 节点 domcontentloaded 内容加载 domcomplete 完毕
navigationStart
加载起始时间
redirectStart
重定向开始时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回开始重定向的 fetchStart 的值。其他情况,则返回 0)
redirectEnd
重定向结束时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回最后一次重定向接受完数据的时间。其他情况则返回 0)
fetchStart
浏览器发起资源请求时,如果有缓存,则返回读取缓存的开始时间
domainLookupStart
查询 DNS 的开始时间。如果请求没有发起 DNS 请求,如 keep-alive,缓存等,则返回 fetchStart
domainLookupEnd
查询 DNS 的结束时间。如果没有发起 DNS 请求,同上
connectStart
开始建立 TCP 请求的时间。如果请求是 keep-alive,缓存等,则返回 domainLookupEnd (secureConnectionStart)
如果在进行 TLS 或 SSL,则返回握手时间
connectEnd
完成 TCP 链接的时间。如果是 keep-alive,缓存等,同 connectStart
requestStart
发起请求的时间
responseStart
服务器开始响应的时间
domLoading
从图中看是开始渲染 dom 的时间,具体未知
domInteractive,加载内嵌的资源,例如图片...
未知
domContentLoadedEventStart
开始触发 DomContentLoadedEvent 事件的时间
domContentLoadedEventEnd 时间节点
DomContentLoadedEvent 事件结束的时间
domComplete
从图中看是 dom 渲染完成时间,具体未知
loadEventStart
触发 load 的时间,如没有则返回 0
loadEventEnd
load 事件执行完的时间,如没有则返回 0
unloadEventStart
unload 事件触发的时间
unloadEventEnd
unload 事件执行完的时间
# 简单用法
DNS 解析时间: domainLookupEnd - domainLookupStart
TCP 建立连接时间: connectEnd - connectStart
白屏时间: responseStart - navigationStart
dom 渲染完成时间: domContentLoadedEventEnd - navigationStart
页面 onload 时间: loadEventEnd - navigationStar
let timing = performance.timing,
start = timing.navigationStart,
dnsTime = 0,4
tcpTime = 0,
firstPaintTime = 0,
domRenderTime = 0,
loadTime = 0;
dnsTime = timing.domainLookupEnd - timing.domainLookupStart;
tcpTime = timing.connectEnd - timing.connectStart;
firstPaintTime = timing.responseStart - start;
domRenderTime = timing.domContentLoadedEventEnd - start;
loadTime = timing.loadEventEnd - start;
console.log('DNS解析时间:', dnsTime , '\nTCP建立时间:', tcpTime, '\n首屏时间:', firstPaintTime,
'\ndom渲染完成时间:', domRenderTime, '\n页面onload时间:', loadTime);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# DNS 域名解析原理及 CDN(内容网络分发)
# DNS
DNS(Domain Name System),域名解析,用于将域名转换成 IP
# 为什么要进行域名解析
一般我们在访问一个网站的时候,我们在地址栏里面输入的是域名,很少有人去输入 IP 来访问。比如说 blog.ctomorrow.top,当我们把这段域名输入到地址栏中后,因为域名是字符串,浏览器是无法解析字符串的,所以要把域名解析成 IP 地址才可以进行访问
# 如何配置域名
当我们在买了云服务器和域名之后,要向让域名与服务器对应必须要进行相关的配置,通常配置面板就会提供商那里。
例如阿里云,在阿里云的域名控制台中就可以看到解析
在这里就可以配置服务
域名资源记录有很多中,分别代表者不同的类型。
# DNS 域名解析
DNS 服务器内部是有一个大数据库的,主要的字段就两列,相当于 key-value 结构。key 是域名,value 是 IP。在进行域名解析的时候,把域名投到 DNS 服务器,然后 DNS 根据域名找到对应的 IP。
DNS 采用迭代查询的方式进行域名解析。首先看下图。
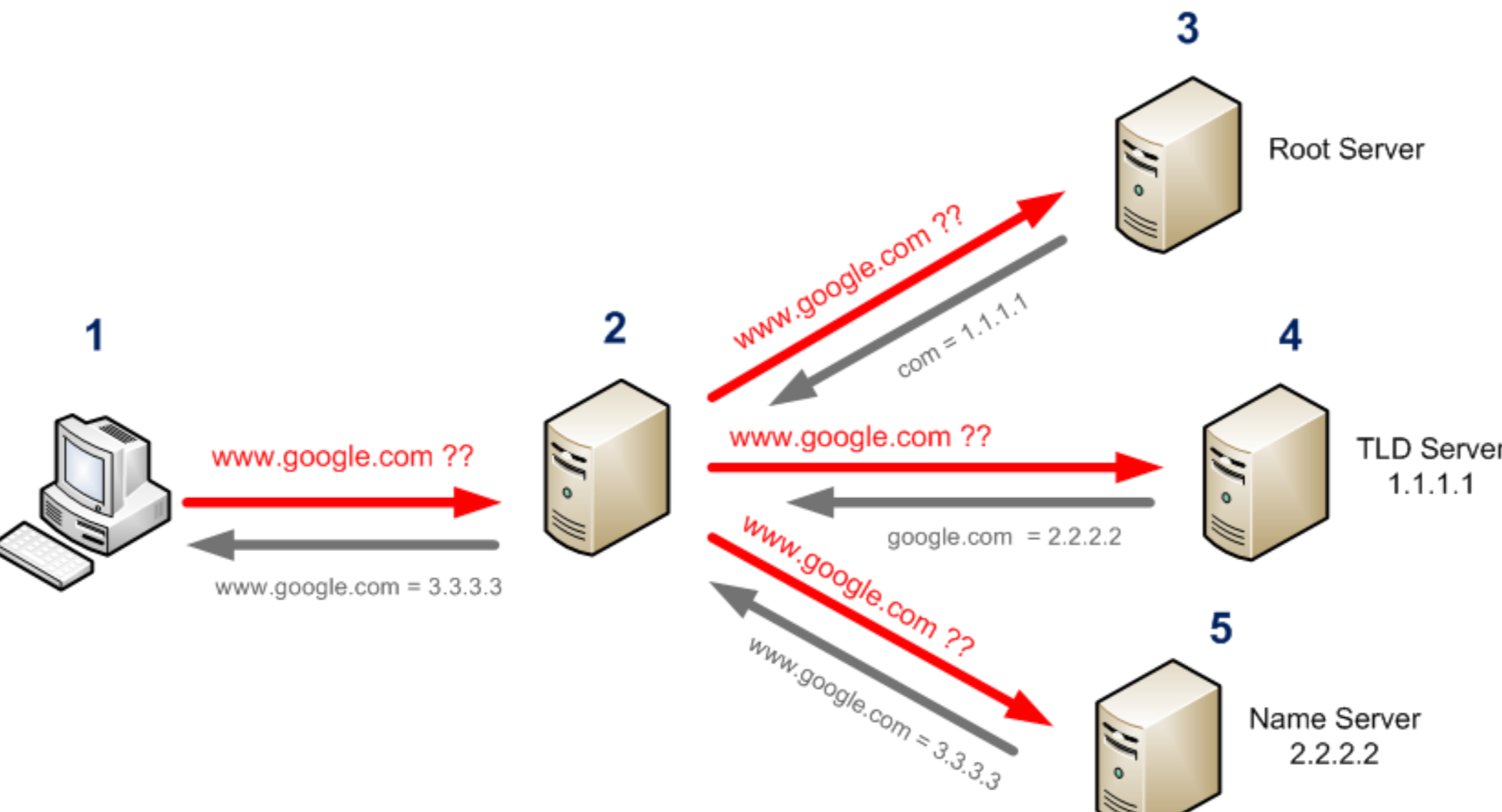
先来解释一下图上的几台主机。
1 号电脑就是我们的客户端,输入 url。
2 号主机就是 DNS 服务器。
3 号主机是 DNS 根服务器,存放顶级域名后缀与相应 TLD 服务器的 IP,用于映射顶级域名后缀的 TLD 服务器的 IP。
4 好主机是 DNS TLD 服务器,存放顶级域名与相应 Name 服务器的 IP,用于映射顶级域名的 Name 服务器的 IP。
5 号主机是 DNS Name 服务器,真正存放 IP 与域名的映射关系在这里,用于映射客户端所访问域名的 IP。
# CDN(内容分发网络)
CDN 的全称是 Content Delivery Network,即内容分发网络。CDN 是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。(CDN 网络是在用户和服务器之间增加 Cache 层,如何将用户的请求引导到 Cache 上获得源服务器的数据,主要是通过接管 DNS 实现)
# CDN 是基于 DNS 域名解析在网络上的一种优化策略。
# 曾经的集中式
在很久以前上网的时候,网站服务器只有一个,客户端很多,每次请求都要走很长很长的网络,访问网站效率很慢。
# 分布式
分布式的出现就是为了解决在访问网站的时候走很长网络的问题。在全球各地都放服务器,在请求的时候判断客户端的地理位置,找到离客户端最近的那台服务器,把请求资源返回给客户端。
# CDN 原理
当用户点击网站页面上的内容 URL,经过本地 DNS 系统解析,DNS 系统会最终将域名的解析权交给 CNAME 指向的 CDN 专用 DNS 服务器。
CDN 的 DNS 服务器将 CDN 的全局负载均衡设备 IP 地址返回用户。用户向 CDN 的全局负载均衡设备发起内容 URL 访问请求。CDN 全局负载均衡设备根据用户 IP 地址,以及用户请求的内容 URL,选择一台用户所属区域的区域负载均衡设备(边缘节点),告诉用户向这台设备发起请求。均衡设备把服务器的 IP 地址返回给用户。
用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务(多级缓存)器请求内容,直至追溯到网站的源服务器将内容拉到本地(回源)。
# TCP 协议及三次握手、四次挥手
# 网络协议模型
网络中的网络协议模型共有两种:一种是网络标准 OSI/ISO 七层协议模型,一种是使用广泛 TCP/IP 五层协议模型。其实这两种都差不多,TCP/IP 五层协议模型是把 OSI/IOS 七层模型的上三层合并成为了应用层。
# 数据在网络上的传输过程
在网络传输上共有两个角色:客户端和服务端。客户端发送请求,服务端响应请求。网络请求在网络协议模型上是一个拆包和封包的过程。
过程如下:
数据发送端每经过一层都会封装上这层协议的协议头部向下传输。例如:对于网络请求来说,在应用层封装上 HTTP 的头部转换成报文,在传输层封装上 TCP 头部转换成数据包,在网络层封装上 IP 的头部转化成 IP 数据报,在数据链路层加上 MAC 地址封装成帧,然后在物理层转换成比特流进行传输。
在物理层传输过程中如果遇到交换机和路由器。遇到交换机把比特流转换成帧,根据交换机所指 MAC 地址重新封装成帧再向下转换进行传输;遇到路由器拆包到网络层,根据路由策略决定向下传的 IP 地址再进行向下封装传输。
经过万里长征终于到达服务器,会在网络协议模型中把第一步骤一一拆解开,最终拿到数据。响应过程中还是这么一套过程。
# 数据通信的三种基本方式
单向通信
单向通信又称单工通信,即只能有一个方向的通信而没有反方向的交互。比如:无线电广播、电视广播这种。
双向交替通信
双向交替通信又称半双工通信,即通信的双方都可以发送信息,但不能同时发送(当然也不能同时接收)。这种通信方式是一方发送另一方只能接受,等发送的一方不发了,接收的一方才可以发送。比如:对讲机等。
双向同时通信
双向同时通信又称全双工通信,即通信的双方都可以同时发送和接受信息。显然,双向通信的传输效率最高。TCP 就是全双工通信。
# TCP
# TCP 协议的特点
TCP 是面向连接的传输层协议
每一条 TCP 协议只能有两个端口
TCP 提供数据的可靠交付服务
TCP 是全双工通信
面向字节流
# TCP 头部
TCP 头部至少 20 字节的数据,如下图:
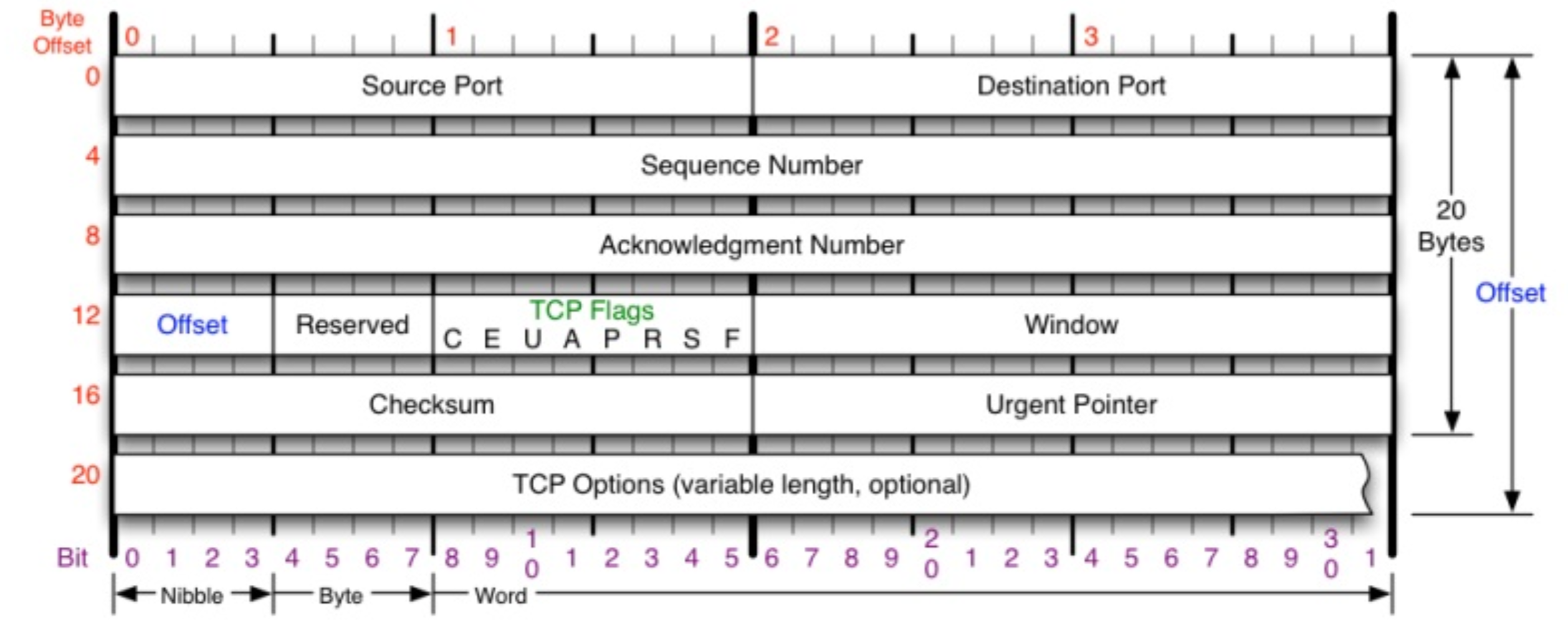
0-4:我们都知道 TCP 协议是保证端到端可靠传输,首先是 4 个字节的目的端口和源端口
4-8:Sequence Number (发包的顺序号)
8-12:Acknowledgment Number (应答号,不同的应答号代表者不同的指令,标记此次动作)
12-16:标记位,偏移量,时间窗口等等
16-20:Checksum(校验码)、Urgent Pointer(偏移指针)
TCP Options TCP 内置的命令(FIN,SYN 就在这里)。
上层数据
# socket 套接字
上面说到 TCP 的特点的时候说道每一条 TCP 只能有两个端口,这端口不是别的,就是套接字端口。
套接字接口的格式:
socket = {IP地址 : 端口号}
2
# 三次握手、四次挥手
为什么三次握手、四次挥手?
TCP 保证的是应用程序之间端到端的可靠传输。要想可靠就必须要有这个机制。
三次握手
三次握手总结如下:
客户端对服务端说:Hi,你能收到我发的信息吗?
服务器对客户端说:我能收到,你能收到我发的吗?
客户端对服务器说:我也能收到。
是不是非常好理解,再来个详细。
开始的时候客户端和服务器的 TCP 连接都处于 CLOSE 状态。当要连接的时候,客户端为主动打开,服务端为被动打开。
一开始服务端服务器进程首先创建传输控制模块 TCB(这其中保存了连接重要的信息),然后服务端就处于 LISTEN 状态。
客户端向服务器发送一个 SYN=1,seq=n(SYN=1,建立连接的标志,seq 为头部的序号位)的数据包,此时客户端进入 SYN_SENT 状态(连接请求已发送)。
服务端接收到客户端发来的请求时,会向客户端发送确认并且请求客户端建立连接(SYN=1、ACK=1、seq=k,ack=n+1),此时服务端进入 SYN_RCVD 状态(连接请求收到)
客户端接收到服务器的确认后,并且还要向服务器发送确认,(ACK=1,seq=n+1,ack=k+1),此时 TCP 建立连接,客户端状态变为 EXTABLISHED(已连接状态)
服务端接受到客户端的确认之后,同样也进入 EXTABLISHED(已连接状态)。三次握手完毕
四次挥手
在此次聊天过程中,突然双方起了争执。
四次挥手总结如下:
客户端对服务端说:我不想听你说话了,不和你聊了(此时客户端已经把手机扔一边了)。
服务端对客户端说:你不想听,我也要说(服务端直男癌犯了,服务端说啥客户端都看不到)。
服务端对客户端说:我也不想和你说话了,冷战吧。
客户端对服务端说:好,冷战就冷战,然后双方删了微信。
开始处于数据传输过程中,双方状态为 ESTABLISHED。
首先客户端向服务端发送 FIN=1,seq=x(FIN=1 是断开连接的标志)的数据包,进入 FIN_WAIT1 状态(终止等待 1)。
服务端接受到客户端的请求,因为服务端这边还要收场,所以先应答客户端,进入 CLOSE_WAIT 状态(关闭等待)。此时 TCP 通信就进入到了半关闭状态。
客户端接收到服务端返回的确定进入 FIN_WAIT2 状态(终止等待 2).
服务端处理好自己的事情之后,向客户端发送一个 FIN=1 的包,进入 LAST_ACK(最后确认)状态。
客户端接收到服务端发送的关闭连接的包,并返回个服务端确认。进入 TIME_WAIT(时间等待)状态,此时 TCP 连接还没有释放点,必须要经过时间等待计数器设置的时间之后(2MSL),才会进入 CLOSED(关闭)状态。 服务端接受到客户端的确认之后,进入 CLOSED(关闭)状态。
客户端时间等待计数器结束之后进入 CLOSED(关闭)状态。TCP 连接释放。
# HTTP 缓存策略
# 缓存的定义
缓存就是数据交换的缓冲区(称作 Cache),这个概念最初是来自于内存和 CPU。当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
# Web 缓存
客户端和服务器之间是通过请求和响应来相互通信的。
# 请求的本质就是从客户端向服务器发起请求,获取服务器资源(图片、文件、数据)返回给客户端。
Web 缓存就是保存从服务器响应的资源,当发起下一次请求请求同样的资源的时候,不需要再请求服务端,直接从缓存中得到
# 缓存类型
HTTP 缓存分为强缓存和协商缓存,共有四种缓存类型
强缓存
浏览器第一次请求服务器时,服务器会将文件和缓存时间一起返回给客户端,客户端将二者备份至缓存数据库中。再次请求数据的时候,客户端会根据文件的过期时间去判断文件是否过期,如果未过期就从缓存数据库中拿文件,如果过期,则重新从服务器上请求文件。
1.Cache-Control
Cache-Control 是优先级最高的强缓存,它有一下值:
Cache-Control: no-cache 必须先与代理服务器确认是否更改,然后在在决定使用缓存还是请求,类似于协商缓存(304)。可以用于不让浏览器自己缓存,我们自己来控制缓存,让文件更可控。
Cache-Control: no-store 才是真正的不缓存数据到本地。
Cache-Control: public 可以被所有用户缓存(多用户共享),包括终端和 CDN 等中间代理服务器。
Cache-Control: private 只能被终端浏览器缓存(而且是私有缓存),不允许中继缓存服务器进行缓存
Cache-Control: must-revalidate 如果缓存内容失效,请求必须发送服务器进行验证。
Cache-Control: max-age=s 设置缓存时间,缓存内容在 s 秒后失效,仅 HTTP1.1 可用
# 第一次请求服务器,响应头会返回一个 max-age,表示文件的缓存过期时间。
# 第二次请求 客户端会校验文件是否过期,如果文件未过期则直接使用本地缓存,返回返状态码 200(from memory cache)或 200(from disk cache),如果过期则进行协商缓存。
2.Expires
Expires 是 http1.0 提出的一个表示资源过期时间的 header,它描述的是一个绝对时间,由服务器返回。正是因为又服务器返回,而服务器时间和本地时间不同,所以它有时候是不准的。
# 浏览器第一次请求服务器,响应头里会返回一个 Expires 的文件过期时间。
# 第二次请求服务器时,客户端使用本地时间和文件的过期时间相比对,如果未过期则直接使用本地缓存返回状态码 200(from memory cache)或 200(from disk cache)则进行协商缓存。
协商缓存
浏览器第一次请求服务器的时候,服务器会将缓存标识和资源一起响应给客户端,客户端将二者备份至缓存服务器。再次请求数据时,客户端将备份的缓存标识发给服务器,服务器根据缓存标识决定是从缓存拿数据还是从服务器上请求数据。如果判断成功,返回 304 状态码,通知客户端从缓存中拿数据;如果判断失败,则再次请求进行缓存。
3.Etag/If-None-Match
Etag 规则是通过文件的内容来判断该不该读缓存,服务器把文件读出来,通过某种方式为文件加上标识(一般是通过 MD5 进行 base64 加密得出 hash 值,把这个值设置在相应头里面),客户端下一次请求通过 If-None-Mach 带过来,服务器再比对和当前文件内容加密得出的 hash 值是否相同,如果相同则说明文件内容没有发生变化,可以从缓存中获取,如果不相同则文件发生变化,重新请求。这种是最准确的方式,同样也是最耗时的。
# 客户端第一次请求服务器,响应头中返回包含文件缓存标识的 Etag 标签。
# 客户端第二次请求服务器,请求头包含 IF-None-Match,服务器获得缓存标识后,用该标识和文件 hash 值进行比对。比对成功,则文件未过期,从缓存中拿返回状态码 304,比对失败,重新请求文件并缓存,返回状态码 200
4.Last-Modified/If-Modified-Since
Last-Modefied 规则是通过文件的最后修改时间来判断该不该读缓存,服务器端设置响应头 Last-Modified,表示最后修改时间。客户端再次请求服务器的时候通过请求头 If-Modified-Since 把最后修改时间提交给服务器,服务器判断客户端返回的时间和文件的时候相比对,如果相等则表示未过期,可以从缓存中拿,如果不相等则表示缓存已过期,再次请求并缓存。
# 第一次请求服务器,响应头中返回 Last-Modified 头,表示文件最后修改时间。
# 第二次请求服务器,请求头中返回 If-Modified-Since 头,把文件最后修改时间返回给服务器,服务器来做决策。
# 什么样的文件可以缓存,什么样是文件不可以缓存?
静态资源可以缓存
动态资源不能缓存
需要根据 cookie 拿到信息不能缓存
post 请求不能缓存
HTTP 头中没有包含缓存策略标记的不能缓存
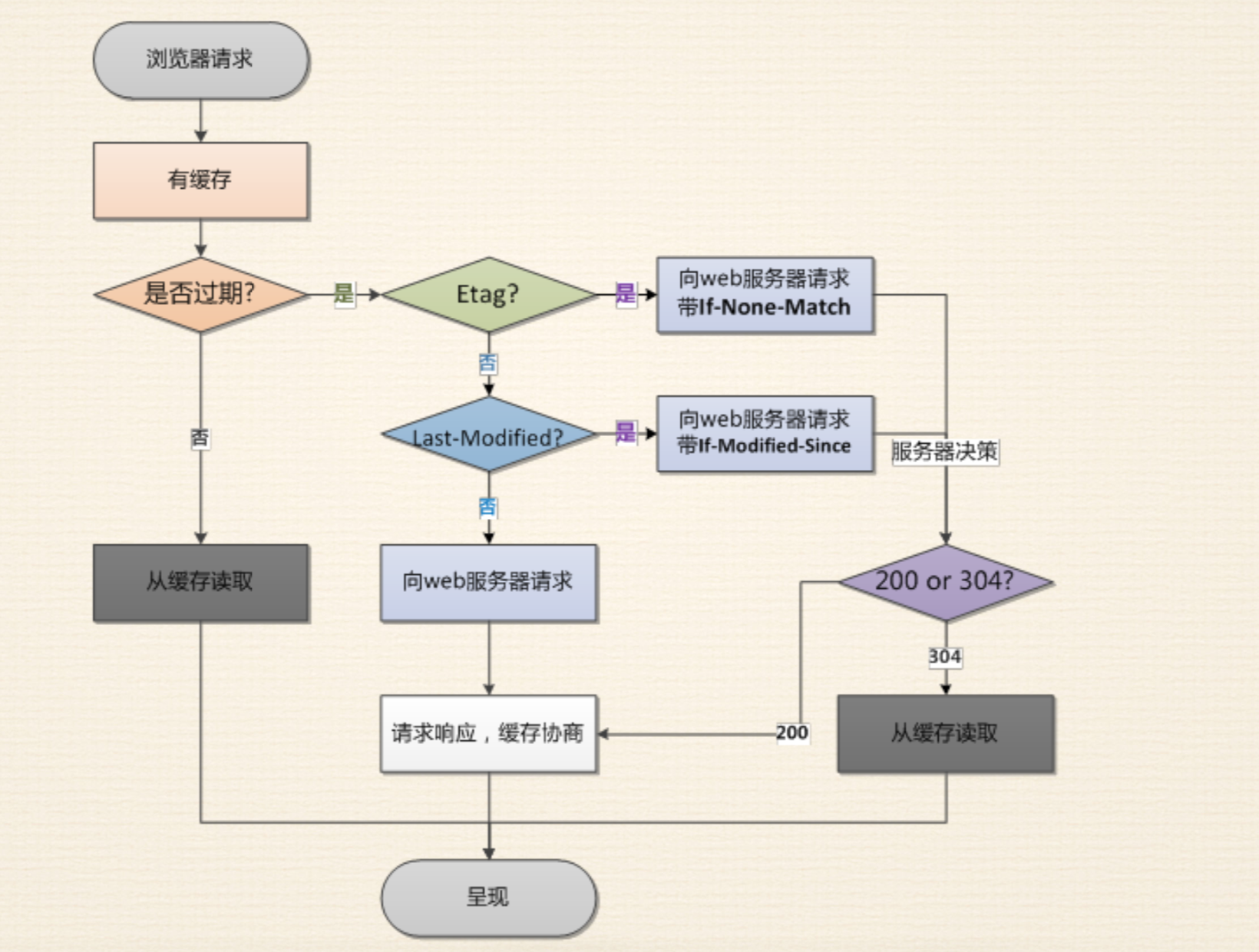
# 缓存策略图
# Nginx 服务器缓存实践
在 Web 缓存中我们一般用,Nginx 作为代理服务器做缓存。这样做比较简单一些。
Nginx 服务器是默认开启 Etag 规则的。可以通过一下几项配置浏览器缓存。
← HTPP 协议那些事 Linux 基础入门 →