# HTPP 协议那些事
# HTTP 请求模型
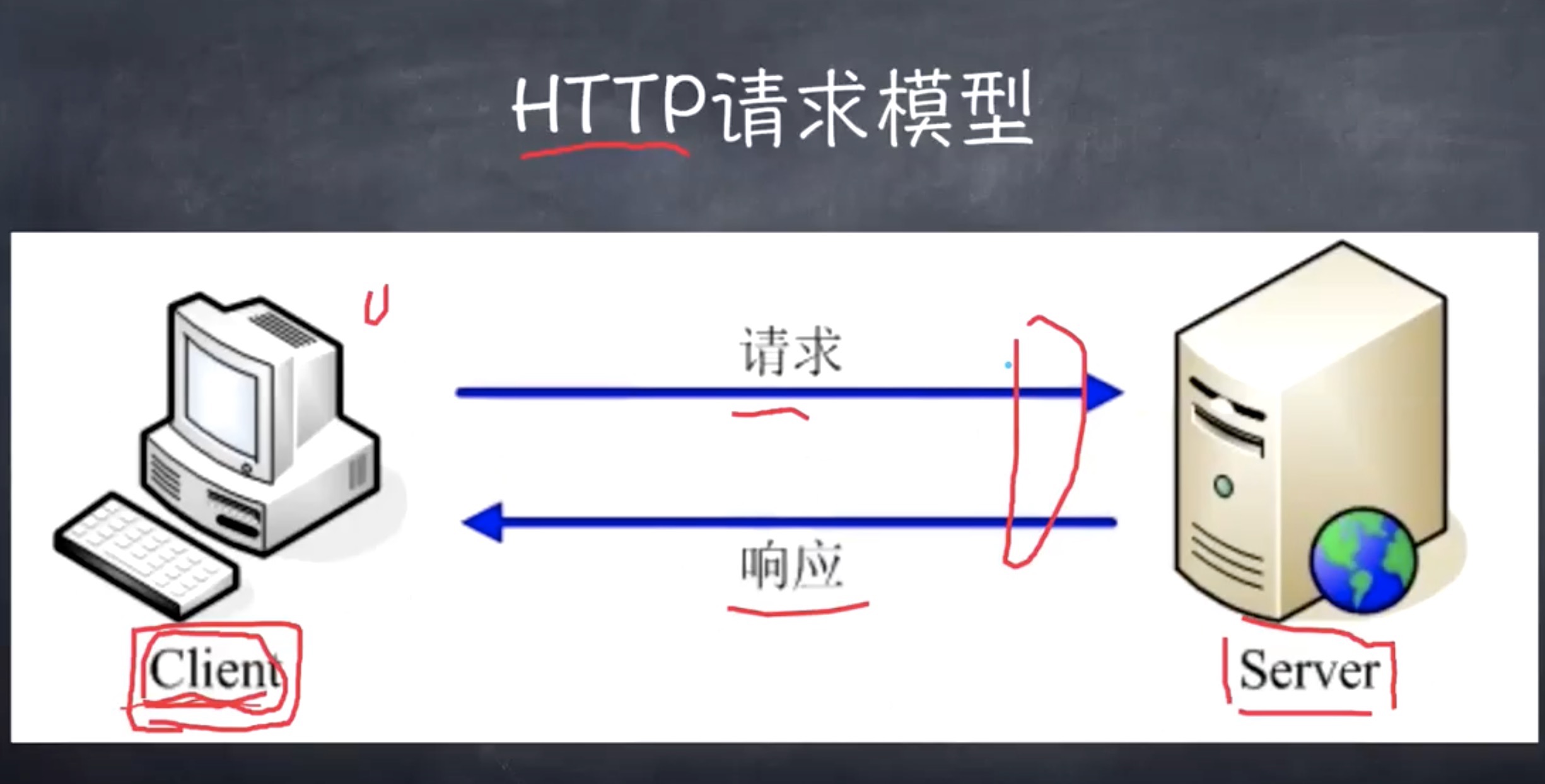
# 两个角色 两个动作
客户端:动作的发起者(通过 HTTP 协议去向服务端请求资源) 服务端:动作的响应者(通过 HTTP 协议去向客户端响应资源)
# 区分客户端和服务端
谁发请求谁是客户端,谁响应请求谁是服务端。
有时候很多软件会把客户端和服务端做在一起:比如 nodejs,nodejs 向前端渲染页面的时候是作为服务端;向真正的后端(java)去请求数据的时候作为客户端。
# 浏览器行为与 HTTP 协议
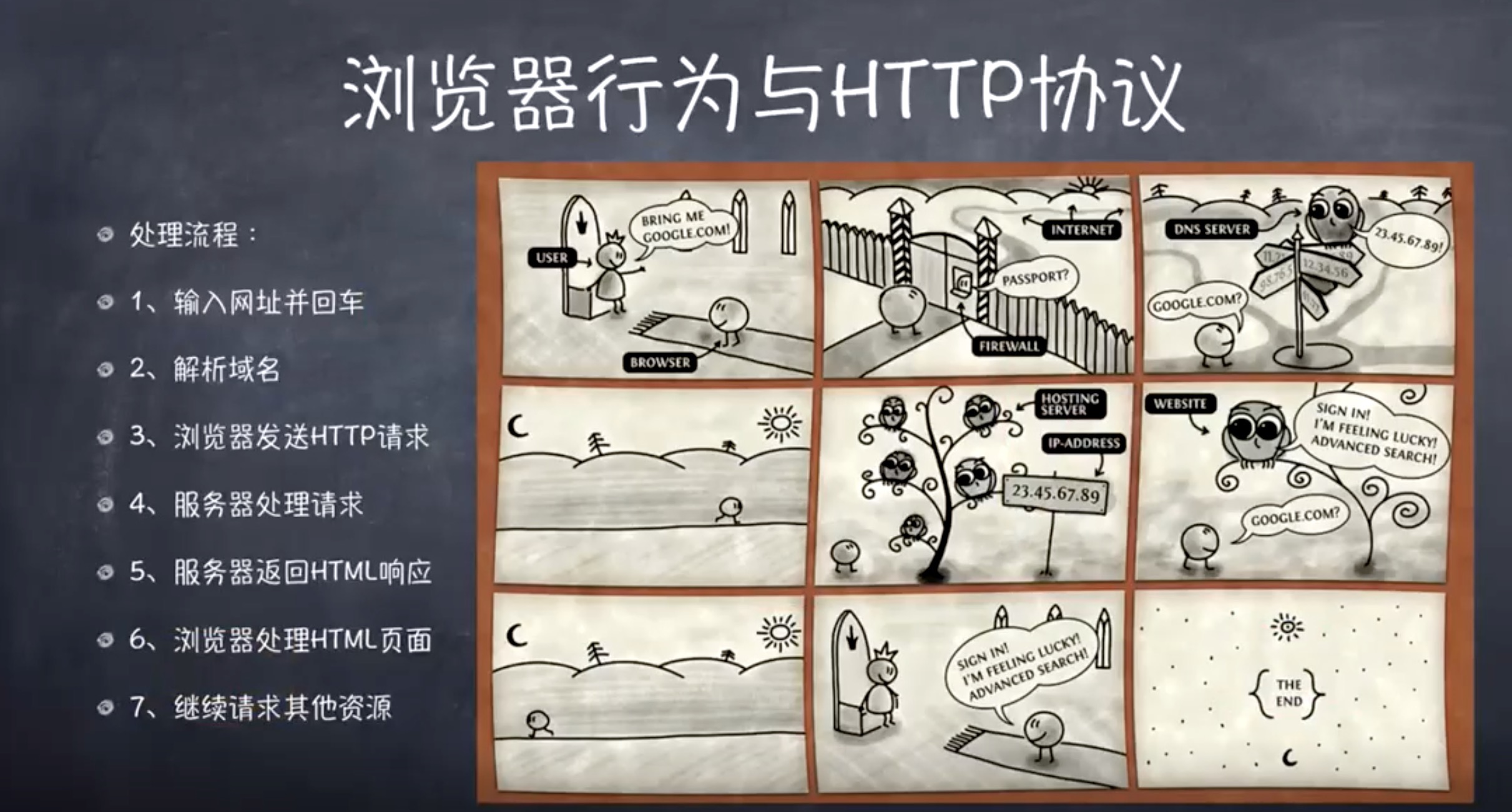
# 处理流程
1.输入网址并回车 准备工作:测试网络的连通性,要保证能够连上互联网。(测试从内网跨越到外网去,这个障碍可能是路由器、网关等等)
Linux 防火墙是是 FireWall 更久以前是 iptables
2.解析域名
输入的网址是一段字符串,必须通过 DNS 服务器做一下 DNS 域名解析。(DNS 就是一个大型数据库,在这个数据库中就维护着域名和 ip 地址的映射关系)
3.浏览器发送 HTTP 请求
Request:向服务器发送请求(通过 5 层协议模型,路由策略(路由转发算法))
4.服务器处理请求
通过 nginx 反向代理找到对应的服务器,然后进行服务器处理。
5.服务端返回 HTML 响应
Response:向客户端响应请求
6.浏览器处理 HTML 页面
浏览器渲染页面
7.继续请求其他资源
浏览器会对 ip 进行缓存,之后的请求是从第 4 步开始,一直请求响应直到把所有要请求的数据全部请求过来为止。
注:请求和响应的路由路径是运营商处理的。DNS 不全是运营商处理,还有第三方的处理(比如说阿里)
第二幅图中一堵墙,可以是防火墙是网关,或者是家用路由器,外面是互联网,里面是局域网
第三幅图拿着第一幅图的地址,其实就是一串字符串,去DNS服务器上(多栏|–|–|)解析成ip地址。ipv4 int
第四幅图透明设备,指的就是我们的路由器。 把我们的数据包转发出去
第五幅图顺着网线终于找到了谷歌的服务器
第六幅图把请求发给服务器
第七幅图通过路由把结果返回给用户
2
3
4
5
6
# 多层协议模型
# OSI/IOS 协议模型
OSI/IOS 协议模型是国际标准模型,共分为七层
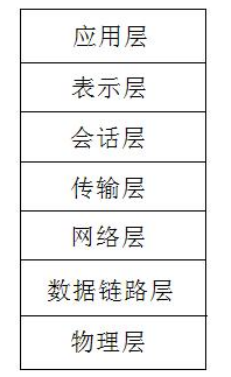
# TCP/IP 协议模型
TCP/IP 协议模型是五层协议模型,对于我们前端来说,下面两层并不是那么关注,也可以说程 4 层协议模型
1.五层:应用层、传输层、网络层、数据链路层、物理层
2.四层:应用层、传输层、网络层、网络接口层
xa

1.应用层
为用户提供所需要的各种服务,例如:HTTP、FTP、DNS、SMTP 等.
2.传输层
为应用层实体提供端到端的通信功能,保证数据包的顺序传送及数 据的完整性。
该层定义了两个主要的协议:传输控制协议(TCP)和用户数据报协议(UDP).
3.网络层
主要解决主机与主机之间的通信问题。IP 协议是网际互联层最重要的协议
ping 命令是用的网络层 . window: trace Linux 与 MAC traceroute 也是网络层的
4.数据链路层
封装成帧、透明传输、差错检测
5.物理层
在物理网线上传送比特流
# 在 TCP/IP 协议栈中的位置

# 什么是 HTPP 协议
HTTP 超文本传输协议,本质就是一种规范,约束响应与请求的动作,被一个组织所制定,在该文档是RFC 文档 (opens new window),是官方的解释。
# HTTP 工作过程
一次 HTTP 操作被称为一个事务,其过程可分为四步:
# 首先理解事务的概念:事务的特点,如果有一个操作,这个操作要分为若干个步骤去完成,而且这个操作要严格遵守这个步骤顺序去操作,同时只要在其中一个步骤中操作失败,那么这次操作就会失败,只要符合这种特点的操作就叫事务
HTTP 操作事务分为四步:
1.首先客户端与服务器需要建立连接(TCP 连接)。只要单击某个超级连接,HTTP 的工作开始。
2.建立连接后,客户端发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后面的 MIME 信息,包括请求修饰符、客户端信息和可能的内容。
3.服务器接收请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号,一个成功或错误的代码,后面是 MIME 信息,包括服务器信息、实体信息和可能的内容。
4.客户端接收到服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户端与服务器断开连接
如果在以上过程中的某一步出现错误,那么产生错误的信息返回到客户端,有显示屏输出。对于用户来说,这些过程是由 HTTP 自己完成的。用户只要用鼠标点击,等待信息显示就可以了。
# 请求与响应
HTTP 请求组成:请求行、消息报头、请求正文
HTTP 响应组成:状态行、消息报头、响应正文
请求行组成:以一个方法符号开头(GET、POST 等等),后面跟着请求的 URI(资源路径)和协议的版本
例如:POST / URI HTTP/1.1
状态行组成:服务器 HTTP 协议的版本,服务器发回的响应状态代码和状态代码的文本描述。
例如:HTTP/1.1 200 OK
# 实际情况下,请求行和响应行会被整合到 General 里面
资源路径 URI:Request URL: https://www.baidu.com/
方法符号:Request Method: GET
协议版本:通常会省略
响应状态吗:Status Code: 200 OK


# 请求头消息报头
# 常用的请求报头
消息报头中都是一些列的键值对来表示的。
. 浏览器所能接受的资源类型
Accept: text/html,application/xhtml+xml;q=0.9,image/webp,image/apng,* / *;q=0.8
. 浏览器所接受的资源是否支持压缩用什么方式压缩(节省时间,节省带宽)
Accept-Encoding: gzip, deflate, br
. 浏览器默认语言是什么
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
.支持长连接(控制长连接和短连接)
Connection: keep-alive
. Host 请求报头域主要用于指定被请求资源的 Internet 主机和端口号,它通常从 HTTP-URL 中提取出来的,发送请求时,该报头域是必需的。
Host: www.baidu.com
. 请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。(根据用户类型判断是不是爬虫,可用于反爬虫)Agent
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1
2
. 请求来源,可用于检查是不是跨域,检查是不是爬虫
Referer: https://www.baidu.com/
# 响应头消息报头
# 常用的响应报头
.缓存相关
Cache-Control:private
Date:Sun, 27 Jan 2019 08:04:07 GMT
Expores:Sun, 27 Jan 2019 08:04:07 GMT
etag
2
. Location 响应报头域用于重定向接受者到一个新的位置。Location 响应 报头域常用在更换域名的时候。
.Server 响应报头域包含了服务器用来处理请求的软件信息。与 User- Agent 请求报头域是相对应的.
Server: BWS/1.1
2
3
# 实体报头
请求和响应消息都可以传送一个实体。一个实体由实体报头域和实体正文组成,但并不是说实体报头域和实体正文要在一起发送,可以只发送实体报头域。实体报头定义了关于实体正文(eg:有无实体正文)和请求所标识的资源的元信息。
# 常用的实体报头
Content-Encoding 实体报头域被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的 附加内容的编码,因而要获得 Content-Type 报头域中所引用的媒体类型,必须采用相应的解码机制。
Content-Language 实体报头域描述了资源所用的自然语言。
Content-Length 实体报头域用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
Content-Type 实体报头域用语指明发送给接收者的实体正文的媒体类型。
Last-Modified 实体报头域用于指示资源的最后修改日期和时间。
Expires 实体报头域给出响应过期的日期和时间。
# 请求方法
GET:请求获取 Request-URI 所标识路径
POST:在 Request-URI 所标识的资源后附加新的数据
HEAD:请求获取由 Request-URI 所标识的资源的响应消息报头(可以用于判断资源有没有变化,查看响应头里面的缓存策略的时间有没有变)
PUT:请求服务器存储一个资源,并用 Request-URI 作为其标识 (用于 RESTful 接口)
DELETE:请求服务器删除不 Request-URI 所标识的资源
TRACE:请求服务器回送收到的请求信息,主要用于测试或判断
COUNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器
OPTIONS:请求查询服务器的性能,或者查询与资源相关的选项和需求
# GET 方法和 POST 方法的区别
来自 w3schools 上面的回答 :
GET 在浏览器回退时是无害的,而 POST 会再次提交请求。
GET 产生的 URL 地址可以被 Bookmark,而 POST 不可以。
GET 请求会被浏览器主动 cache,而 POST 不会,除非手动设置。
GET 请求只能进行 url 编码,而 POST 支持多种编码方式。
GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会被保留。
GET 请求在 URL 中传送的参数是有长度限制的,而 POST 么有。
对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制。
GET 比 POST 更不安全,因为参数直接暴露在 URL 上,所以不能用来传递敏感信息。
GET 参数通过 URL 传递,POST 放在 Request body 中。
更深层次的理解:
HTTP 是基于 TCP/IP 的关于数据如何在万维网中如何通信的协议。因此 GET 和 POST 的根本是 TCP
GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)plainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplainplain
对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200
ok(返回数据)
并不是发一次包就快,发两次包就慢。据研究,在网络环境好的情况下,发一次包的时间和发两次包的时间差别基本可以无视。而在网络环境差的情况下,两次包的 TCP 在验证数据包完整性上,有非常大的优点。
# 并不是所有浏览器都会在 POST 中发送两次包,Firefox 就只发送一次
# HTTP 状态码

# cookie 与 session
HTTP 是一个无状态协议:什么状态?是维持服务器与客户端连接通信的状态。
为了维持这样的状态,引入了 session,session 需要 cookie 配合。
# cookie
Cookies 是保存在客户端的小段文本,随客户端点每一个请求发送该 url 下的所有 cookies 到服务器端。
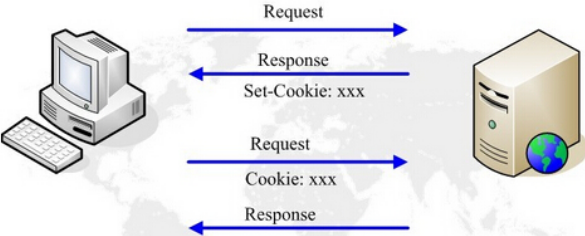
# 与 Cookie 相关的 HTTP 扩展头
Cookie:
BAIDUID=E5CEF5D82F43CCE6E493882174E3B741:FG=1;
BIDUPSID=E5CEF5D82F43CCE6E493882174E3B741;
PSTM=1544774928;
BD_UPN=123353;
__cfduid=de8eb2f58580a76ba2732bfe5c805bf7b1546698346;
BDORZ=B490B5EBF6F3CD402E515D22BCDA1598;
delPer=0;
BD_HOME=0;
BD_CK_SAM=1;
PSINO=2;
locale=zh;
H_PS_PSSID=1454_21111_18559_28329_22160;
BDSFRCVID=WdFsJeCCxG3Javo9Eee93qR0uQmm7Y5SS3lS3J;
H_BDCLCKID_SF=JJkO_D_atKvjDbTnMITHh-F-5fIX5-RLf5cRa-OF5lOTJh0RyxOrDTFkbfDf-pT7KCJD0tJLb4DaStJbLjbke6oWeH0ft6KsKKJyLR-8bn5_Hn5k5KTjhPr2bl5y2RJyb6r20C6jb-cjfTu4DT8BjT5HDG-Jq6-qHJue_II5JDvRehQRy4oTLnk1DP6K-t483CT-VCOhLDJhVJ6zjpuh0pJyhb-eBjT2-DA_oCDbfCTP;
BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm;
BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm;
BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Cookie 中最重要的是 ID,开始的时候客户端是没有这个 ID 的,当第一次请求的时候服务器会给客户端分配 ID,这个 ID 相当于凭据(VIP)以后再来请求的时候,客户端带这个 ID,服务器看到这个 ID,就知道曾经来请求,服务器就是在 session 中记录。
# 设置 cookie
请求头 Cookie:客户端将服务端设置的 Cookie 返回到服务器
响应头 Set-Cookie:服务器向客户端设置 Cookie
服务器在响应消息中用 Set-Cookie 头将 Cookie 的内容回送给客户端,客户端在新的请求中将相同的内容携带在 Cookie 头中发送给服务器从而实现会话的保持。
Set-Cookie: delPer=0; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=15; path=/
Set-Cookie: BD_HOME=0; path=/
Set-Cookie: H_PS_PSSID=1454_21111_18559_28329_22160; path=/; domain=.baidu.com 记录的数据,可以自己设置
2
3
4
# session
session 就是一个小数据库,记录这给客户端的编号,它的身份和其他的信息。
session 永远是存在服务器端的。session 中的 sessionID 服务器维护,服务器根据 session 判断用户。

# session 与 cookie 的区别和特点
cookie 是浏览器这边的一个小数据库,session 是服务器这边的一个小数据库
cookie 是临时的,session 也是临时的。
# HTTP 缓存机制
缓存会根据请求保存输出内容的副本,例如:html 页面,图片,文件,当下一个请求来到的时候:如果是相同的 URL,缓存直接使用副本响应访问请求。而不是向源服务器再次发送请求。

# 缓存的优点
1.减少相应延迟
2.减少网络带宽消耗
# 缓存策略
Etag/If-None-Match 策略
Last-Modified/If-Modofoed-Since 策略
# 两种缓存机制
1.强制缓存:服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存;不在时间内,执行比较缓存策略。
2.比较缓存:将缓存信息中的 Etag 和 Last-Modified 通过请求发送给服务器,由服务器校验,返回 304 状态码时,浏览器直接使用缓存。
# 缓存机制

# HTTPS 协议分析
# HTTPS 使用不对称加密法
对称加密法:加密和解密的可逆的。同样的方法加密可以用同样的方法解密
不对称加密法:加密和解密不是可逆的,加密是一种手段,解密是另外一种手段。基于数论的,对素数的一种性质进行运算。
# HTTPS 协议的安全性由 SSL 协议实现,当前使用的 TLS 协议 1.2 版本包含了四个核心子协议: 握手协议、密钥配置切换协议、应用数据协议及报警协议
每个加密协议都需要数字证书这样的文件。
数字证书:数字证书是互联网通信中标识双方身份信息的数字文件,由CA签发。
CA:CA(certification authority)是数字证书的签发机构。作为权威机构,其审核申请者身份后签发数字证书,这样我们只需要校验数字证书即可确定对方的真 实身份
2
3
4
# HTTPS 协议、SSL 协议、TLS 协议、握手协议的关系
HTTPS 是 Hypertext Transfer Protocol over Secure Socket Layer 的缩写,即 HTTP over SSL,可理解为基于 SSL 的 HTTP 协议。HTTPS 协议安全是由 SSL 协议实现的。
SSL 协议是一种记录协议,扩展性良好,可以很方便的添加子协议,而握手协议便是 SSL 协议的一个子协议。
TLS 协议是 SSL 协议的后续版本,本文中涉及的 SSL 协议默认是 TLS 协议 1.2 版本
# HTTP2 协议分析
# HTTP2 协议的特点
使用二进制格式传输,更高效、更紧凑
对报头压缩,降低开销。
多路复用,一个网络连接实现并行请求
服务器主动推送,减少请求的延迟
默认使用加密
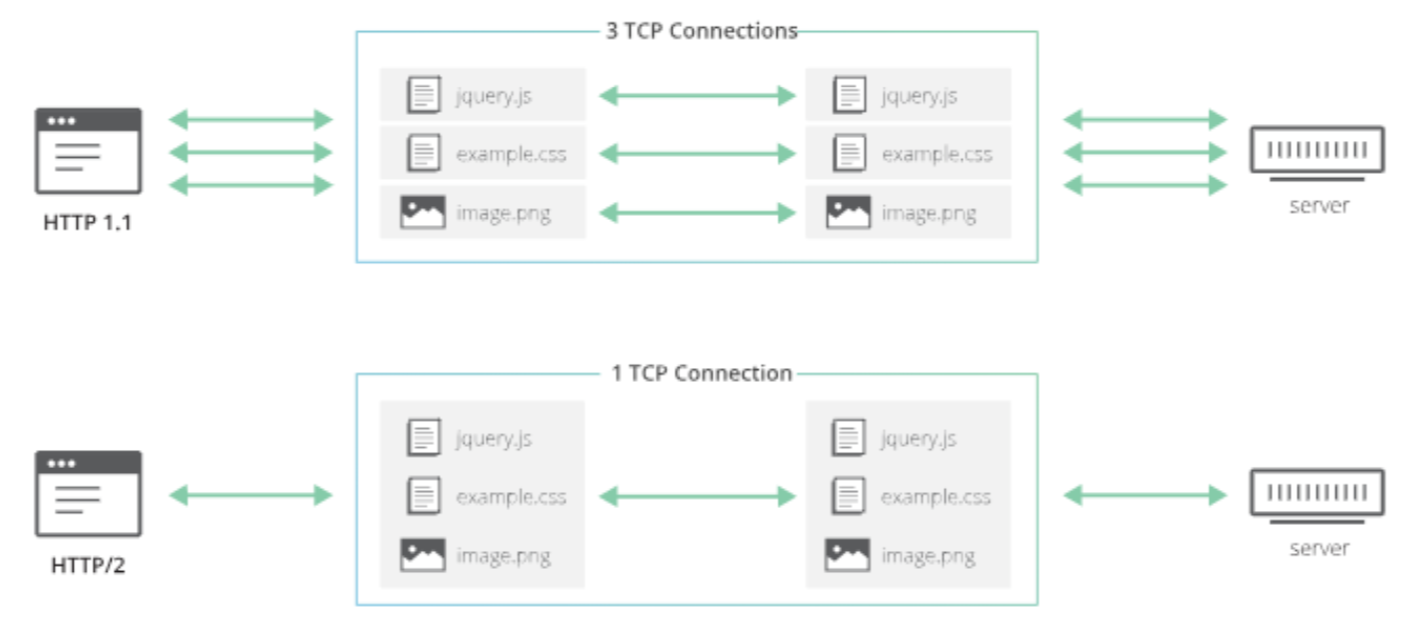
# HTTP2 的伪头字段
伪头部字段是 http2 内置的几个特殊的以”:”开始的 key,用于替代 HTTP/1.x 中请求行/响应行中的信息,比如请求方法,响应状态码等
:method 目标 URL 模式部分(请求) :scheme 目标 URL 模式部分(请求) :authority 目标 RUL 认证部分(请求) :path 目标 URL 的路径和查询部分(绝对路径产生式和一个跟着”?”字符的查询产生式)。(请求) :status 响应头中的 HTTP 状态码部分(响应)
# 如何分辨 HTTP1.1 还是 HTTP2
第一种是看请求头里面有没有:这样的请求字段
第二种是看请求里面有没有明确的标识协议的类型。
# 了解 HTTP 3
1.HTTP-over-QUIC 被更名为 HTTP 3
2.QUIC 协议是什么
基于 UDP(被改造的 UDP)
3.HTTP 3 与 HTTP 1.1 和 HTTP 2 没有直接的关系 4.HTTP 3 不是 http2 的扩展 5.HTTP 3 将会是一个全新的 WEB 协议 6.HTTP 3 目前处于制订和测试阶段
# HTTP 与反向代理
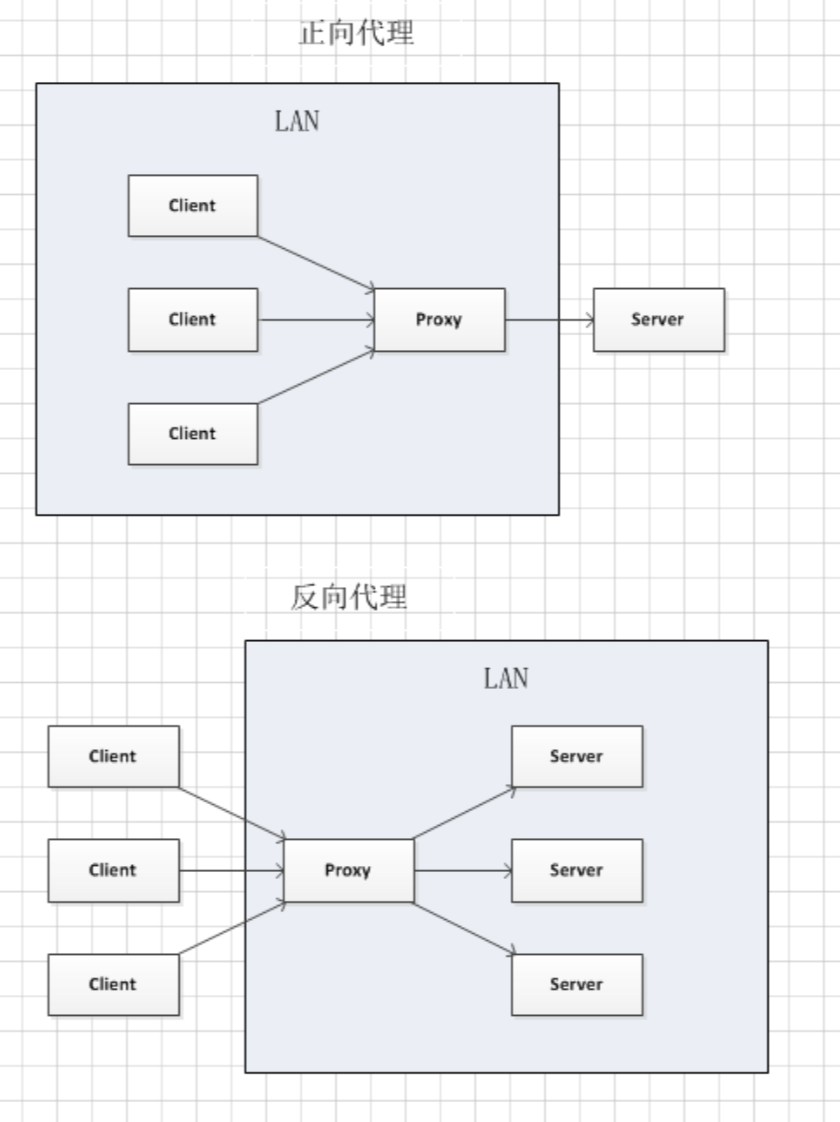
正向代理:局域网内通过代理服务器去访问局域网外的东西这就叫正向代理。
反向代理:互联网外的客户端通过代理服务器访问内网的服务器叫做反向代理。
反向代理就像一个公司看大门的老大爷,当我们去这家公司去找人的时候,首先经过的就是大门。我们向大爷说找谁,大爷给我们传信说:xxx 有人找。这就达到了反向代理的作用。
# 反向代理的用途
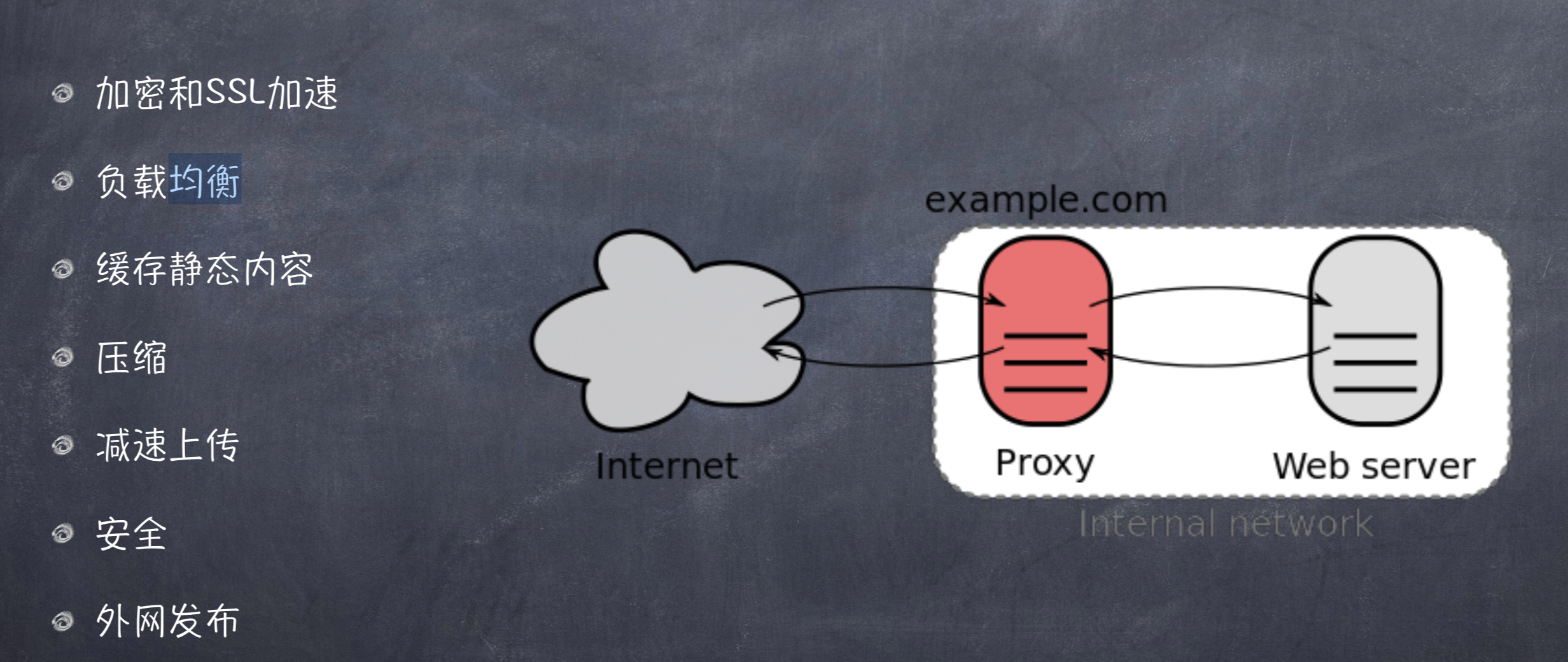
# 反向代理做负载均衡
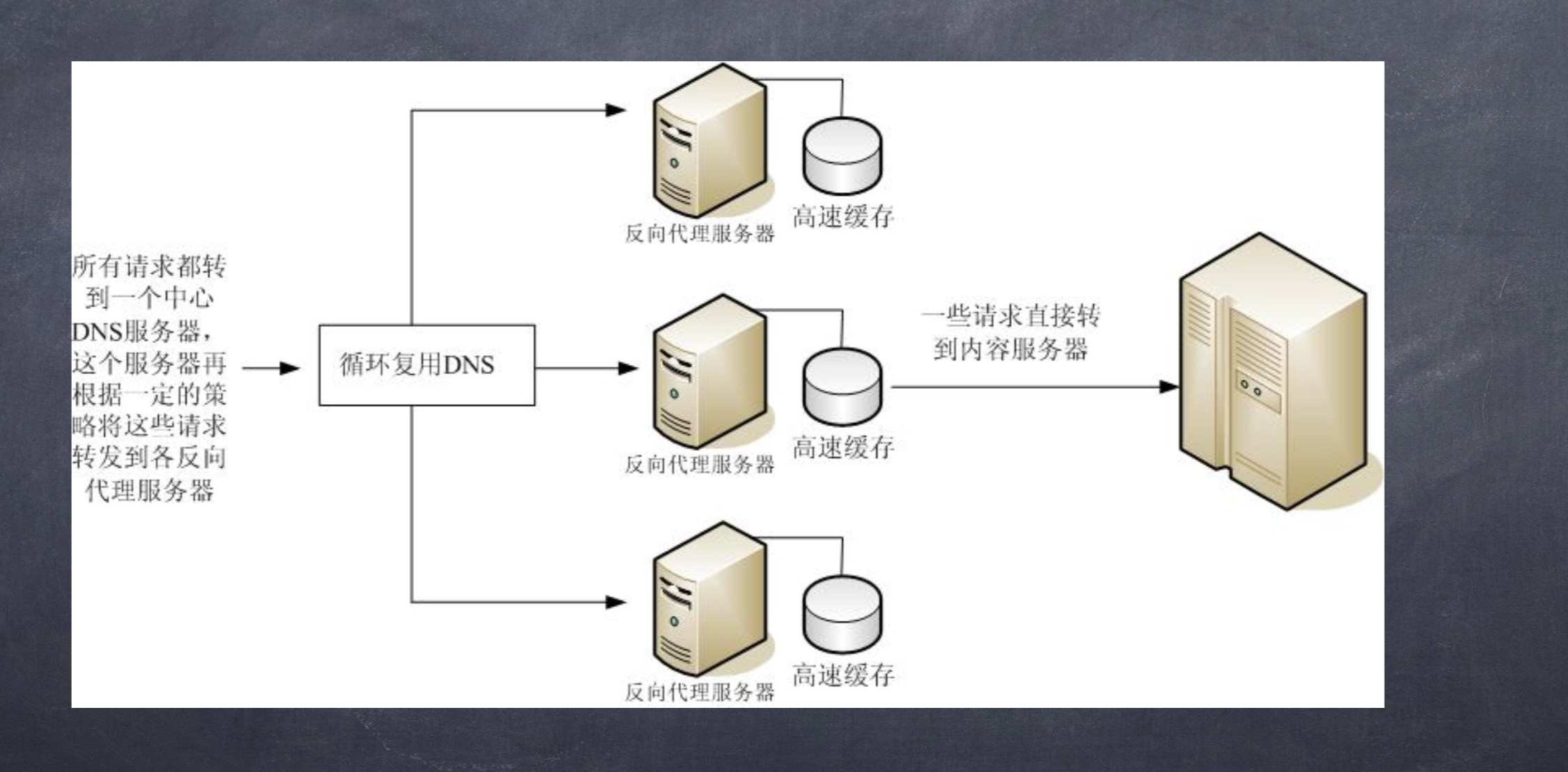
# Nginx 反向代理和负载均衡总结
# Nginx
nginx 是一款 HTTP 服务器和代理服务器。Nginx 功能丰富,除了上面的功能之外还可以支持 FastCGI、SSL、Virtual Host 、 URL Rewrite 、 Gzip 等功能。并且支持很多第三方模块扩展。
# Web 缓存
Nginx 可以对不同的文件做不同的缓存处理,配置灵活,并且支持 FastCGI_Cache,主要用于对 Fast CGI 的动态程序进行缓存。配合着第三方的 ngx_cache_purge,对指定的 URL 缓存内容可以进行增删管理。
# Nginx 配置
Nginx 配置请看文档 (opens new window)